Paper read <<The Convergence of Source Code and Binary Vulnerability Discovery – A Case Study>>
Background
最近阅读了一篇论文<<The Convergence of Source Code and Binary Vulnerability Discovery – A Case Study>>,很巧合的是论文的研究中,关于将SAST工具应用于二进制文件(通过decompiler),即获取伪代码之后,在伪代码上跑SAST工具来找漏洞这个模式我和@C0ss4ck一起做过,在我们收到一些成效之后发现也有人做了类似的工作,不过他好像没有特别深入 :D
我们这做主要是因为一些不可说的原因,最开始是@C0ss4ck搞的用IDAPython搞的工具,但是由于做适配比较麻烦不够灵活;后来我提出了decompiler+weggli的做法的时候,我们都不是那么的看好,但是搞了一些demo发现确实可行,对于一些简单的漏洞模型是可以召回的,主要的瓶颈就在decompile code的质量和规则的编写了,同时由于weggli本身不支持数据流,并且主要是过程内的漏洞模式匹配(AST regexp),所以后面就又面临瓶颈的问题了;在我做调研的时候,发现了这篇新鲜的论文,在读完之后感触良多,对decompiler+SAST的做法也有了更多的理解。
Read this PAPER
这篇论文讨论了源码/伪代码+SAST工具在漏洞挖掘上的效果,以及对于伪代码+SAST这种模式的局限性的探究,对其中的误报&漏报根本原因的分析。
关于论文中的实验设计

- 源码直接使用 SAST 工具
- 多种decompiler反编译之后获取伪代码,丢给SAST工具
- 伪代码修正之后(达到可编译的程度,有些复杂目标要裁剪),给SAST工具用
工具 & 目标选择
尝试召回 real world vulns
基本上都是优秀的工具,其中两款商业工具并没有写具体是啥,但是这个 Comm_1看起来好像Coverity :) 不管怎么样,其中的 codeql和joern我很感兴趣,毕竟可以自定义规则,这对我来说无疑是更好的,可以召回更多问题 & 适用于更多的场景。
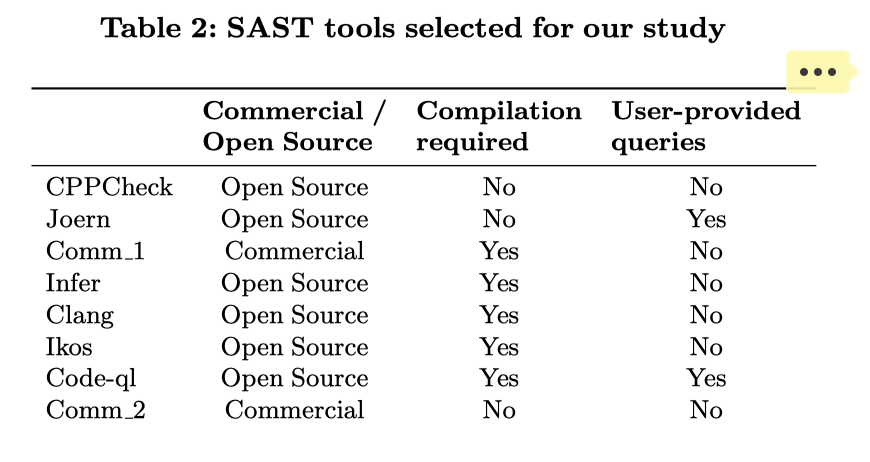
对于漏洞的选择,该论文也选的比较广泛,各种类型都有,复杂度也够,可以更好的“测量”这些工具 :)

结论
反编译代码并不是开箱即用的
对于二进制文件,
伪代码+SAST的模式可行,但是有限SAST工具设计上是给源码用的,这是by design的;二进制文件丢失了关键信息(尤其是编译器优化的影响),不适合给SAST工具做分析,这也是为什么论文中说不用LLVM Lifter的原因decompilers are still designed to generate code that is easy to understand for humans, and SAST tools are still designed to parse “well-written” code that is not generated by a machine.
编译器优化很有意思,有些漏洞因为优化inline,所以从过程间–>过程内,decompile之后的代码反而找到了漏洞 :)
优化的话, 两个思路,相当于朝着同一个方向前进的路:
- 提高反编译代码的质量
- 优化
SAST工具,让其适配反编译的代码
漏报 & 误报 Root cause
个人认为比较核心的地方了
P1 - Inability to Recover the Size of Stack Buffers
经过编译优化,下面的代码中s1由于是指向了为初始化内存,所以可能会报告成栈溢出


说是这样说,但是我个人认为,这种情况是可以避免的,通过汇编是可以判断出来这个 stack buffer 有多大,这种误报理论上是可以排出的,前提是收集更多的信息 <– 优化项
P2 - Signed and Unsigned Integers

没什么好说的,变量类型分析错误,在对伪代码中产生误报正常,这个如果不人为干预,确实没办法
P3 - Integer Operations on Uninitialized Variables
由于缺少必要的信息,导致在 sub 129CF丢失了a2和a4的信息,导致SAST工具产生误报

P4 - Function Pointers
函数指针问题,这个很巧合,前两天请教@jmpews的时候,提到了decompiler+SAST的做法,当时我问的是 joern,大佬的说法是C更不好整, c++ 还可以走 demangle

上面的代码反编译之后得到:

基本上是无法分析的,就算是人肉逆向,也要重建这个结构体,然后转换变量类型,自动化不太现实,这块的误报确实没办法
P5 - Pointers as Integers
还是变量类型的问题,反编译代码对特定变量类型分析错误,导致的误报

反编译之后:

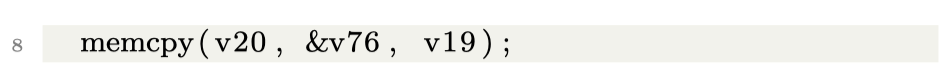
P6 - Integers of Wrong Size
对v22 和 v26 类型识别错误,混用了 uint8_t 和 int64,所以可能会误报整数溢出 :(

P7 - Simplified Expressions
这是一类特殊情况

这里显然把||和&&搞混了,但是反编译之后

这类表达式在编译器优化处理之后,再反编译,该表达式已经看不出来了,就会漏报这个问题 :(
Futher work
decompiler+SAST可行,但是需要优化,能覆盖的场景也有限,目前来看IoT场景是比较适合的,比如各种奇葩的命令注入,显然是可以召回的。
- 最好不要选依赖编译的SAST工具,如codeql
- 选择可以自定义规则的工具
- 最好可以支持过程间分析、数据流
- 为了弥补反编译代码的不足,可以结合汇编层面收集一些信息,比如栈上变量的大小
个人来一个大胆的构想,从ctree上收集信息,生成codeql那样的rel db,目前来看比较接近的是joern,但是它是基于ghirda,优化空间还是有的。
Reference
https://dl.acm.org/doi/10.1145/3488932.3497764
https://security.humanativaspa.it/automating-binary-vulnerability-discovery-with-ghidra-and-semgrep/