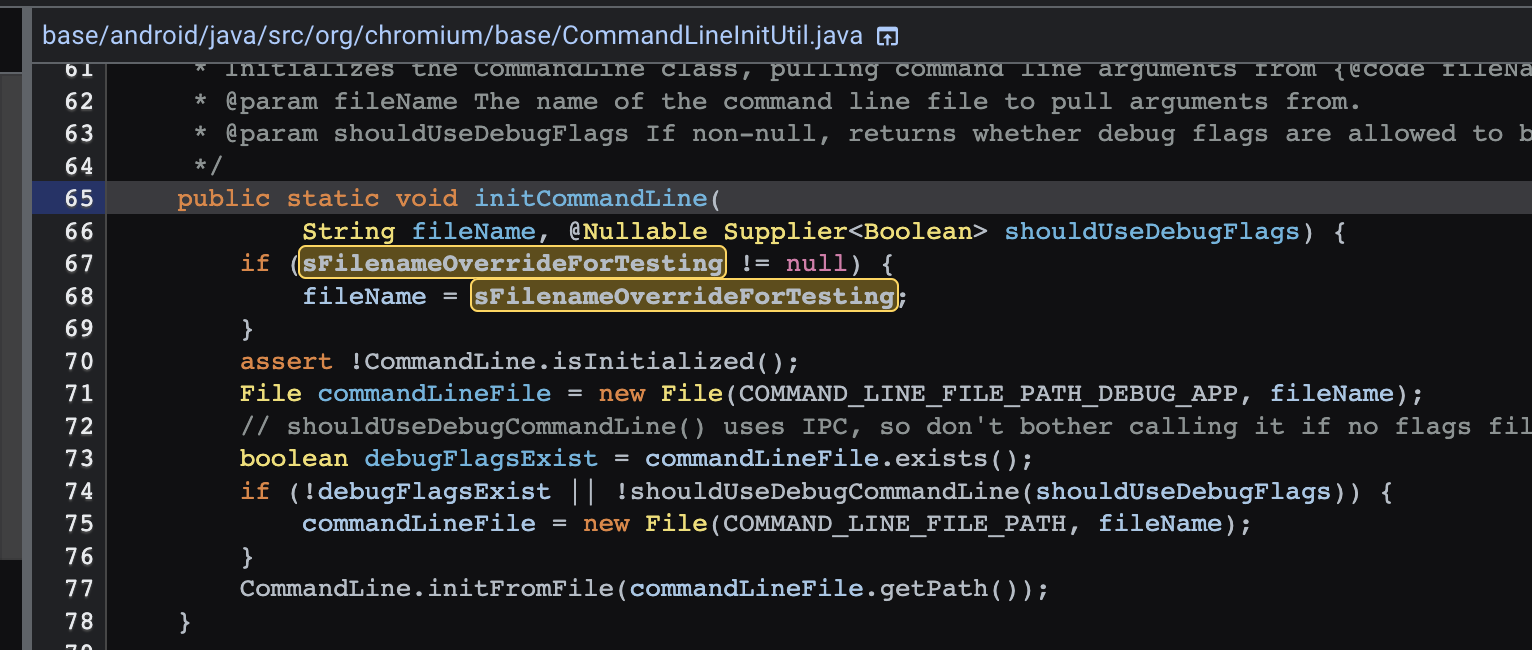
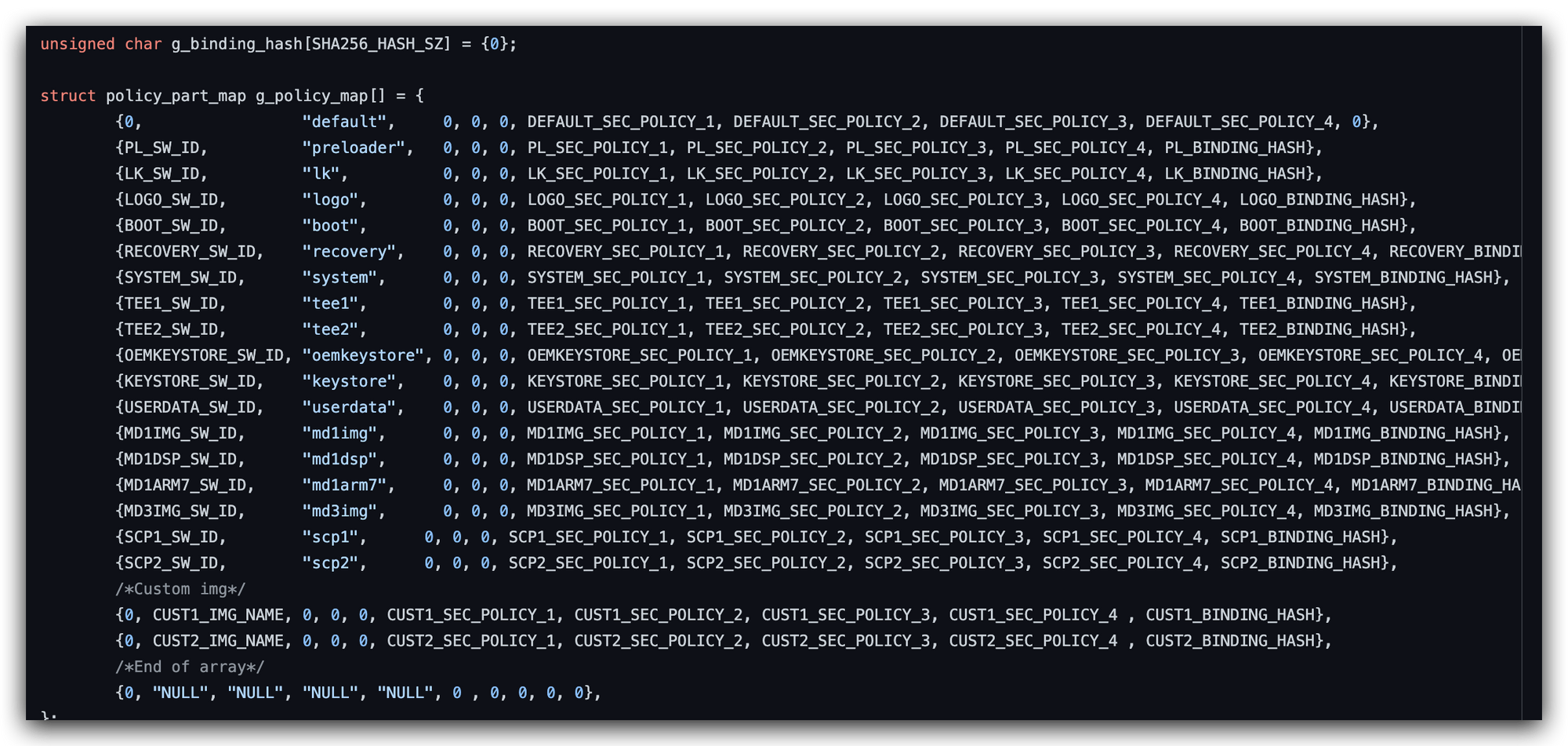
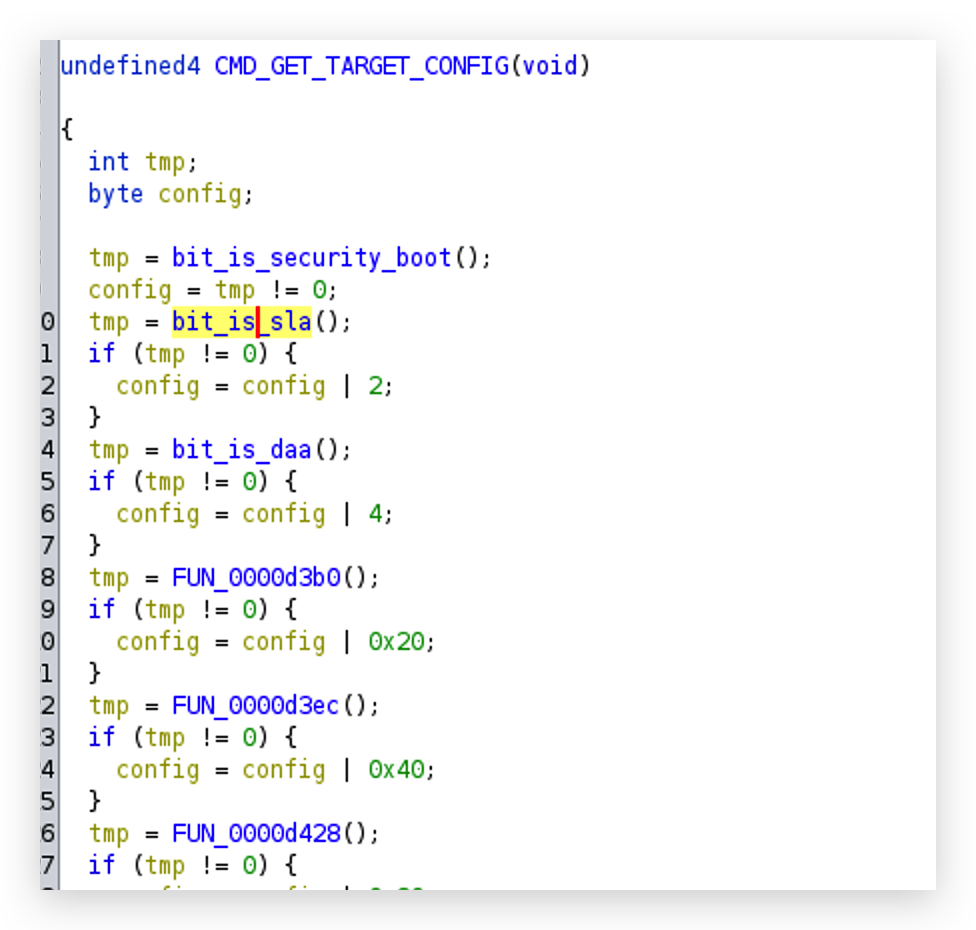
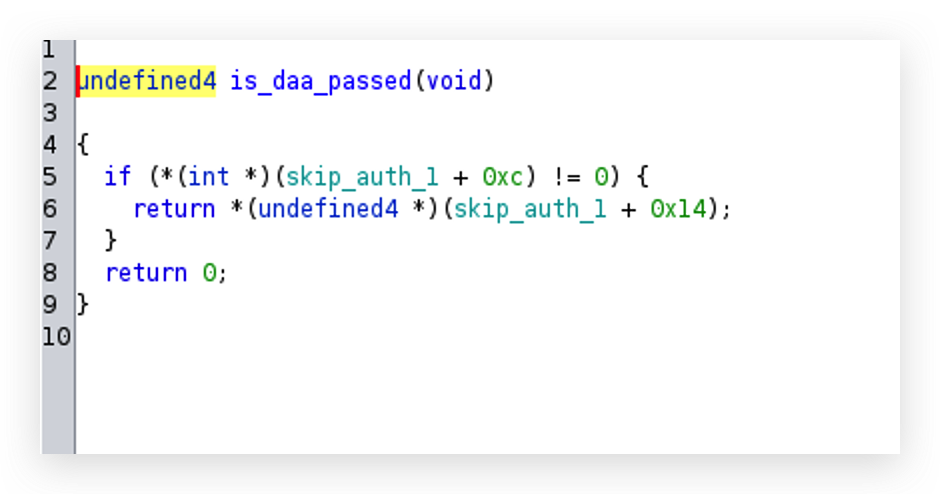
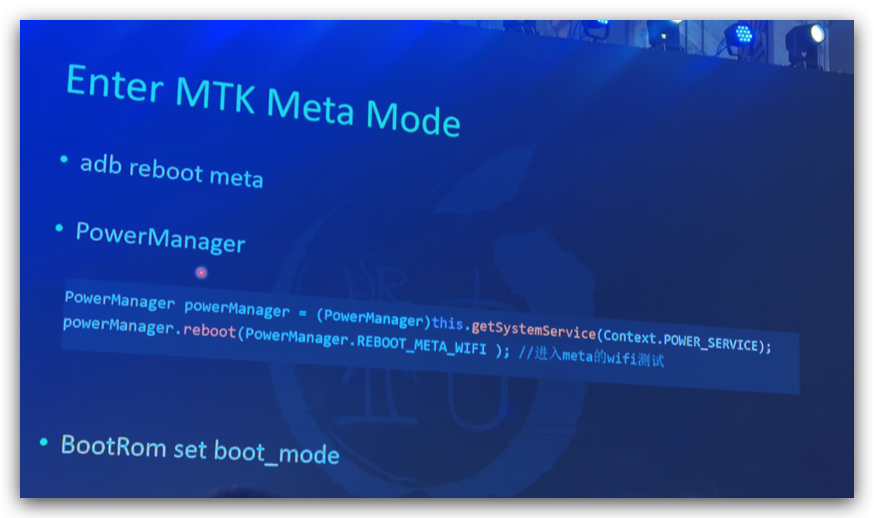
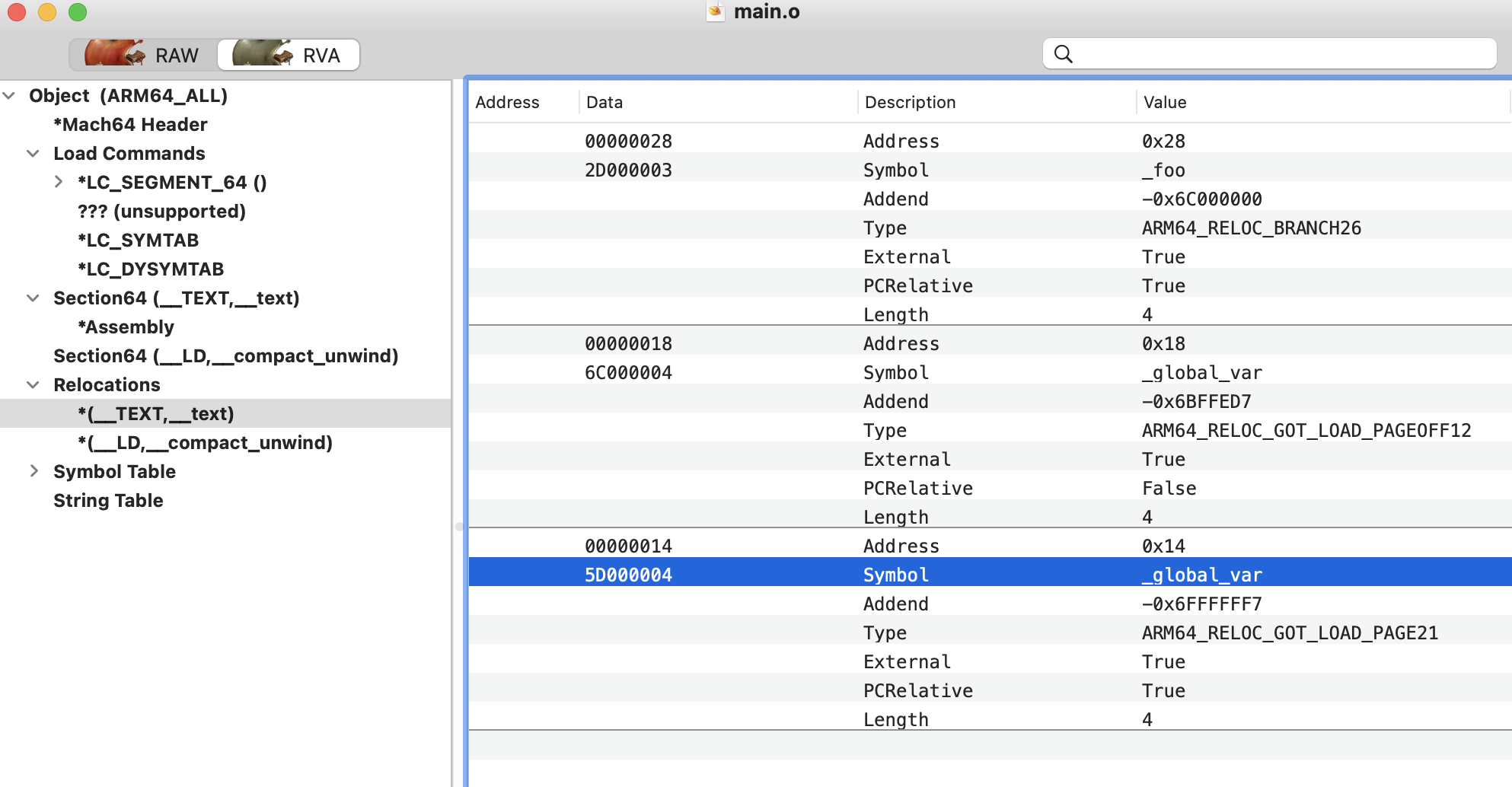
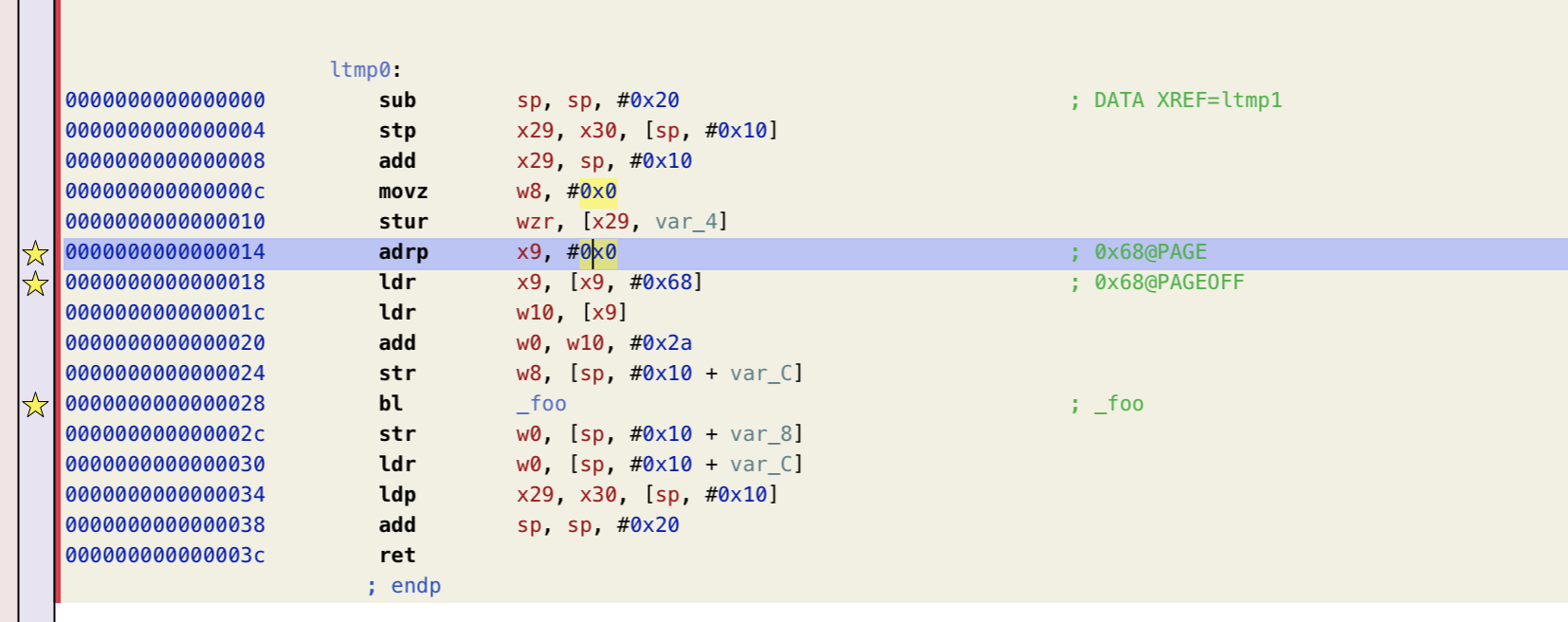
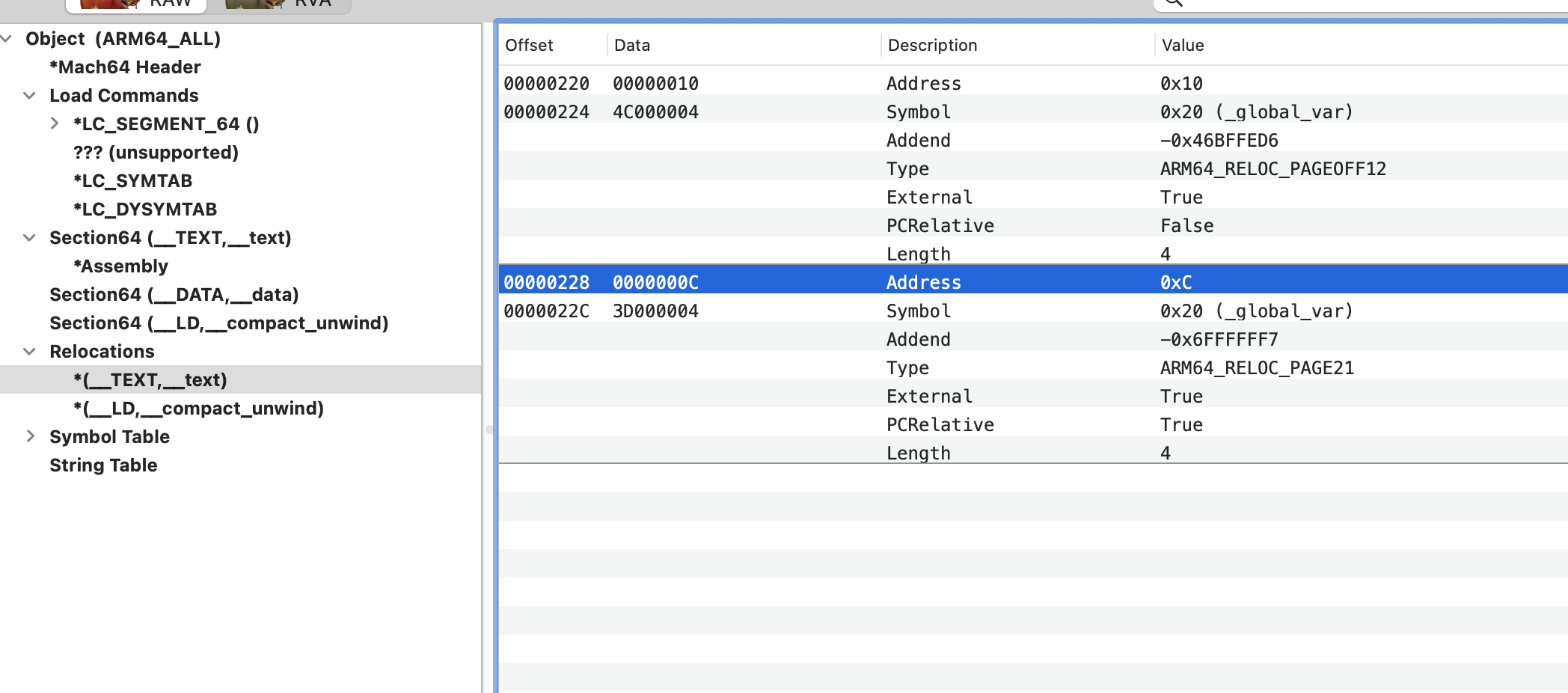
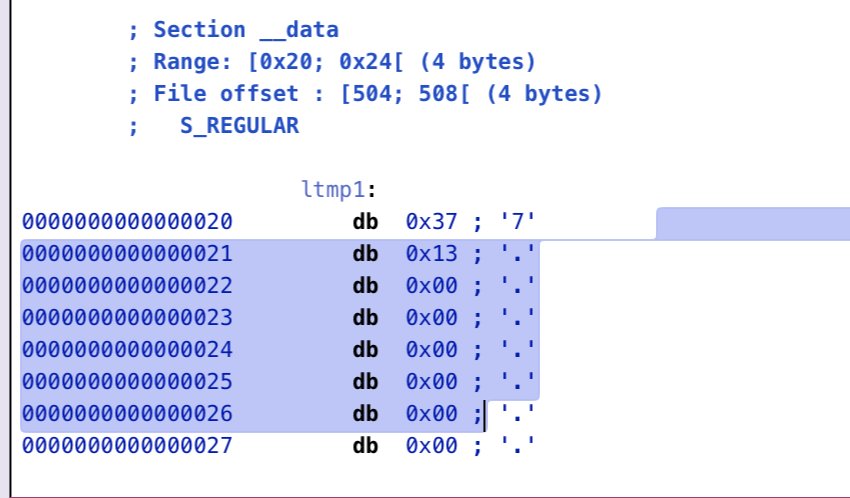
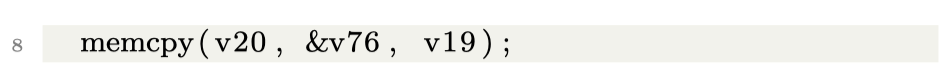o0xmuhe's blog0x414243444546 ????2023-09-09T08:26:59.674Zhttps://o0xmuhe.github.io/muheHexoChromium based browser/Webview启用--js-flagshttps://o0xmuhe.github.io/2023/09/08/Chromium-based-browser-Webview%E5%90%AF%E7%94%A8-js-flags/2023-09-08T09:44:55.000Z2023-09-09T08:26:59.674Z背景
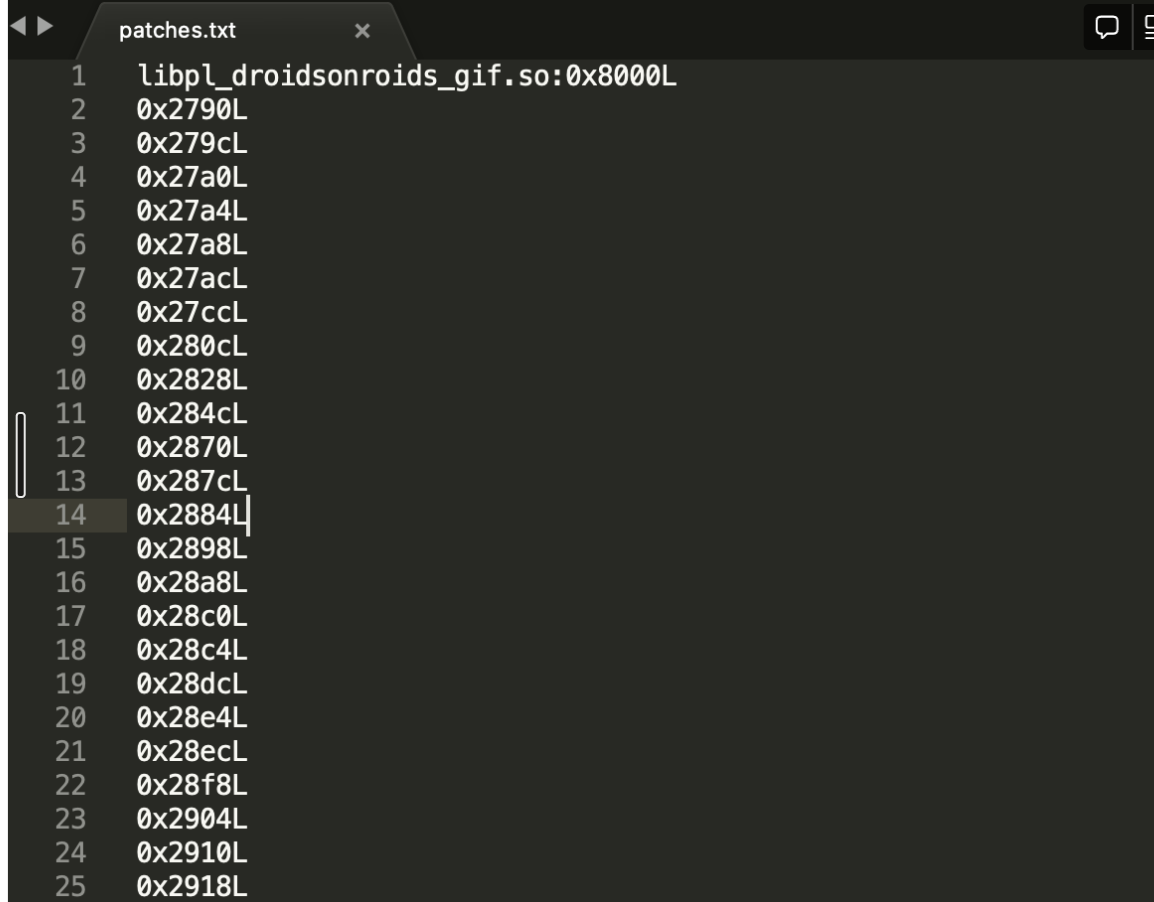
FLAG_FILE=/data/local/tmp/webview-command-line # Overwrite flags (supports multiple). The first token is ignored. We use '_' # as a convenient placeholder, but any token is acceptable. adb shell "echo '_ --highlight-all-webviews --force-enable-metrics-reporting' > ${FLAG_FILE}" # Clear flags adb shell "rm ${FLAG_FILE}" # Print flags adb shell "cat ${FLAG_FILE}"
/** * databases.ts * ------------ * Managing state of what the current database is, and what other * databases have been recently selected. * * The source of truth of the current state resides inside the * `DatabaseManager` class below. */
/** * The name of the key in the workspaceState dictionary in which we * persist the current database across sessions. */ const CURRENT_DB = "currentDatabase";
/** * The name of the key in the workspaceState dictionary in which we * persist the list of databases across sessions. */ const DB_LIST = "databaseList";
/* if log is disabled, re-init log port and enable it */ if (comport->type == COM_USB && log_status() == 0) { mtk_uart_init(UART_SRC_CLK_FRQ, CFG_LOG_BAUDRATE); log_ctrl(1); }
dlcomport = comport;
while (1) { platform_wdt_kick();
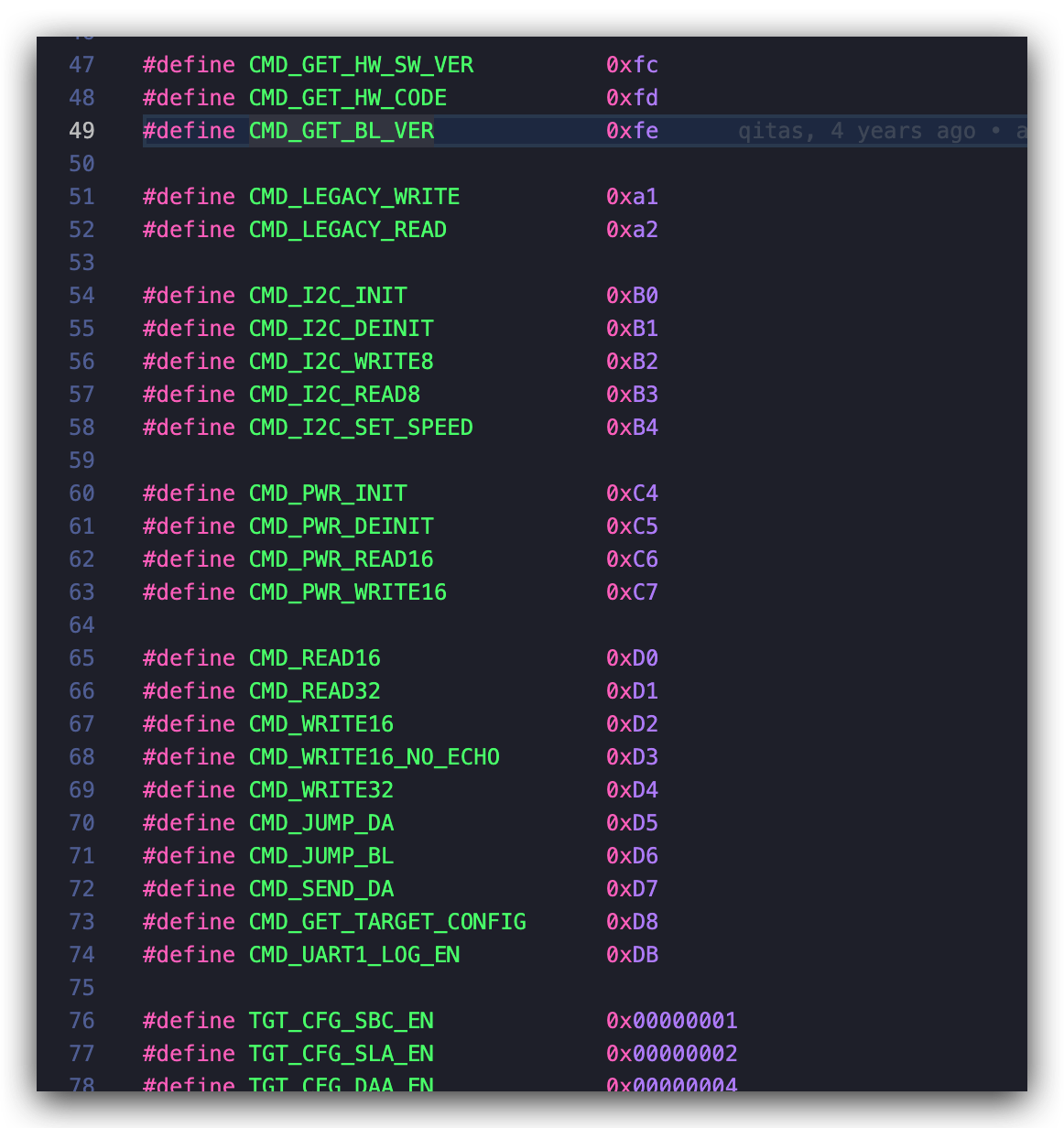
usbdl_get_byte(&cmd); if (cmd != CMD_GET_BL_VER) usbdl_put_byte(cmd); /* echo cmd */
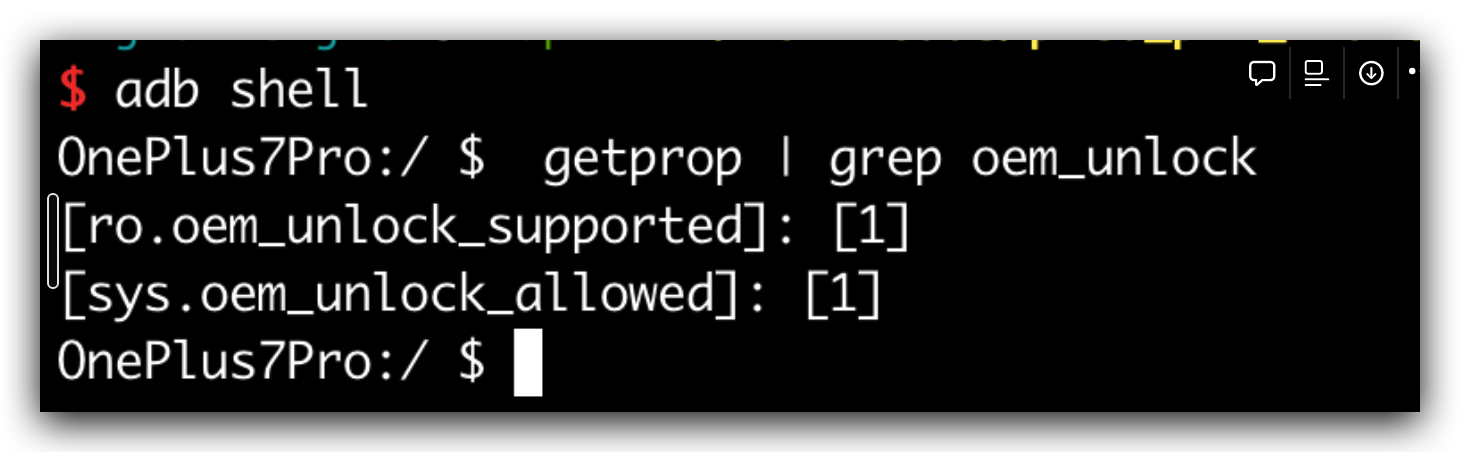
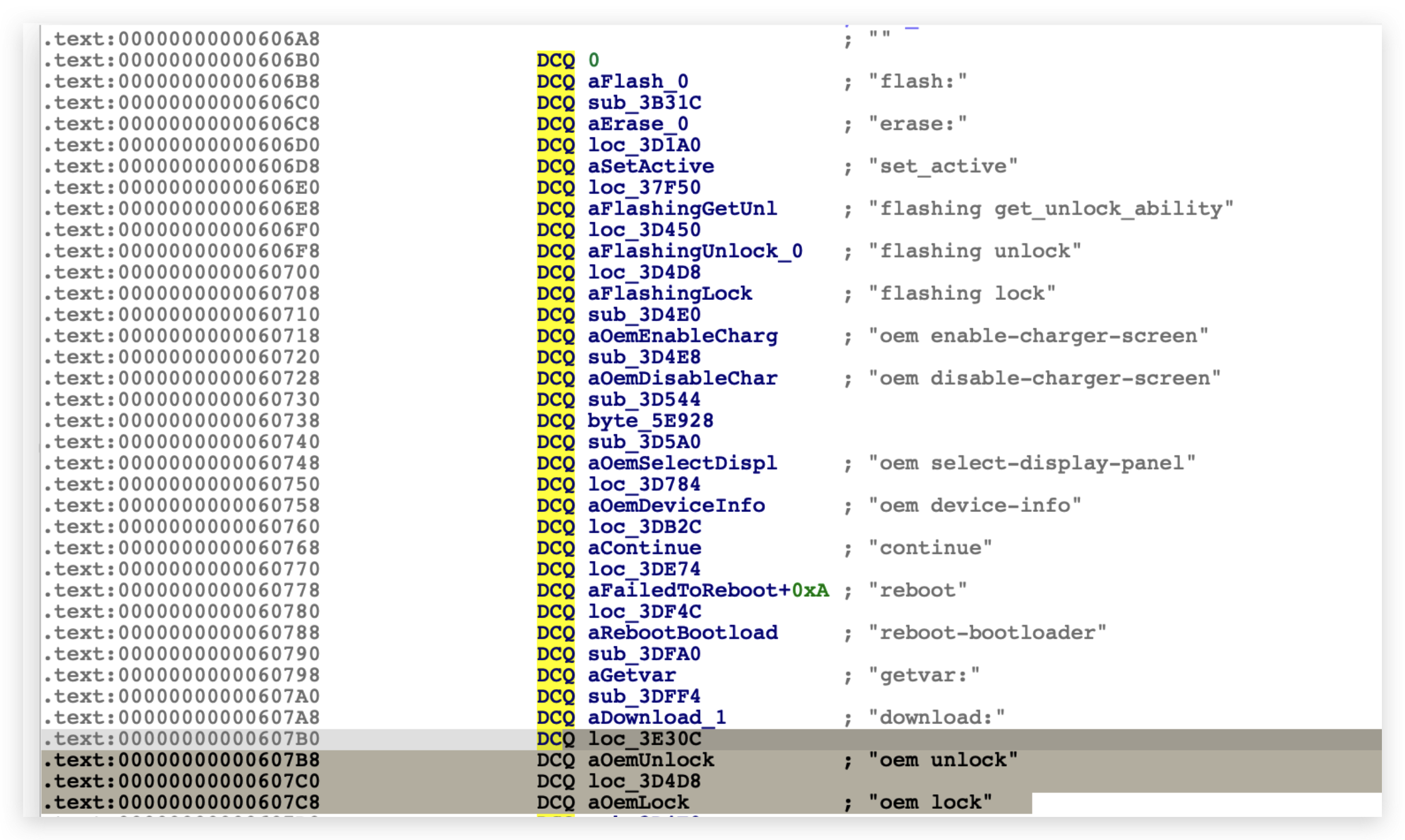
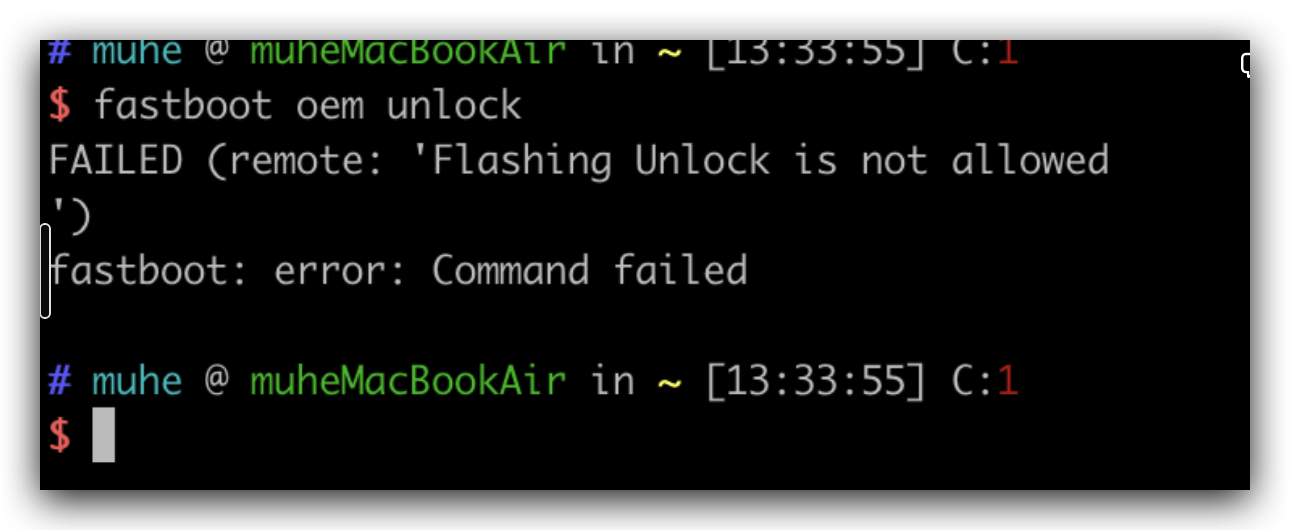
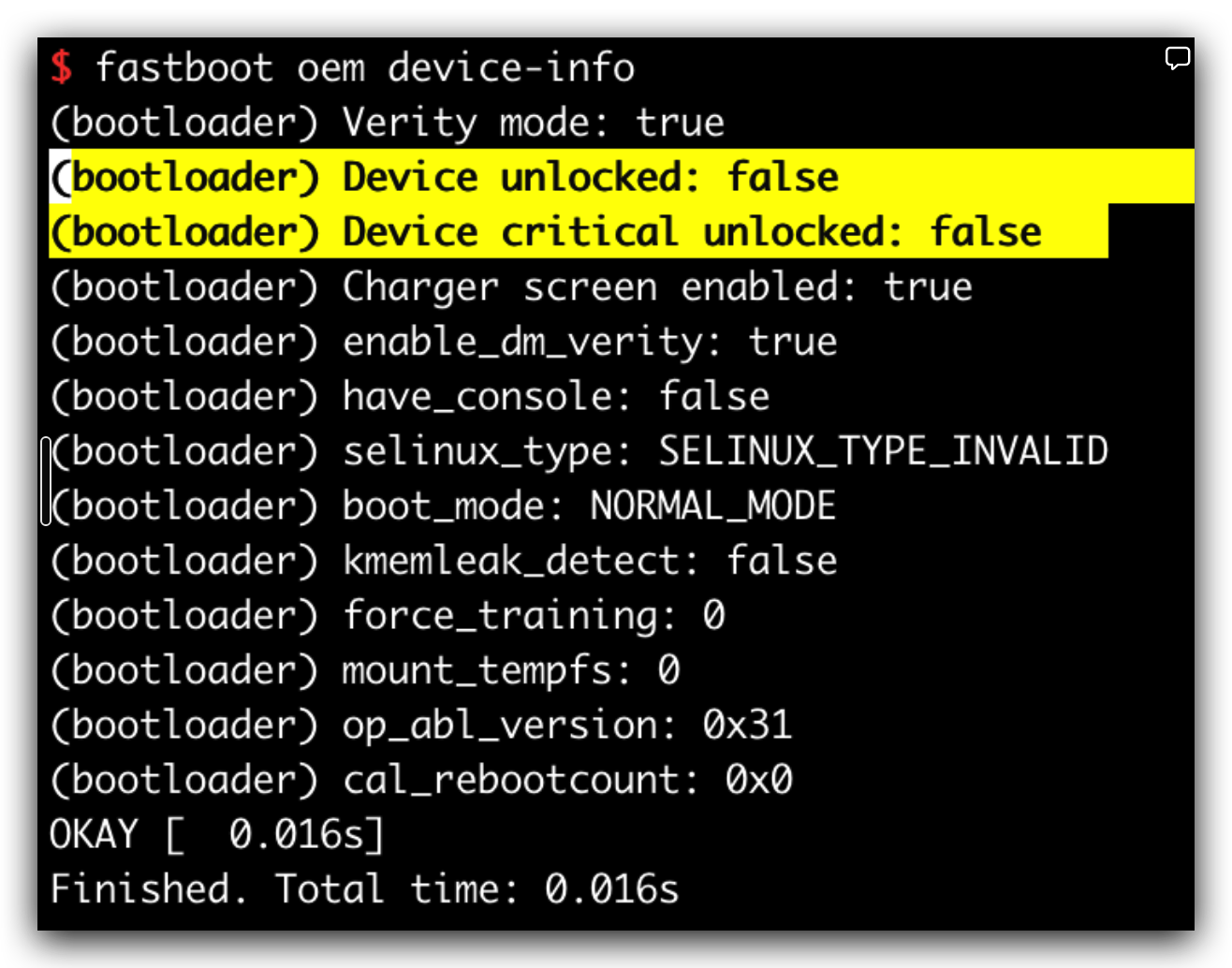
// The user has the final say so if they allow unlock, then the device allows the bootloader // to OEM unlock it. @Override publicvoidsetOemUnlockAllowedByUser(boolean allowedByUser){ if (ActivityManager.isUserAMonkey()) { // Prevent a monkey from changing this return; }
/** * Always synchronize the OemUnlockAllowed bit to the FRP partition, which * is used to erase FRP information on a unlockable device. */ privatevoidsetPersistentDataBlockOemUnlockAllowedBit(boolean allowed){ final PersistentDataBlockManagerInternal pdbmi = LocalServices.getService(PersistentDataBlockManagerInternal.class); // if mOemLock is PersistentDataBlockLock, then the bit should have already been set if (pdbmi != null && !(mOemLock instanceof PersistentDataBlockLock)) { Slog.i(TAG, "Update OEM Unlock bit in pst partition to " + allowed); pdbmi.forceOemUnlockEnabled(allowed); } }
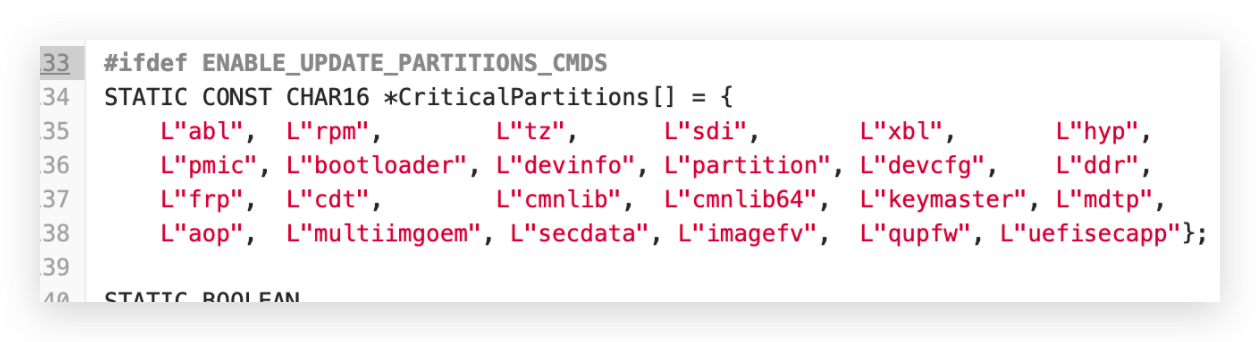
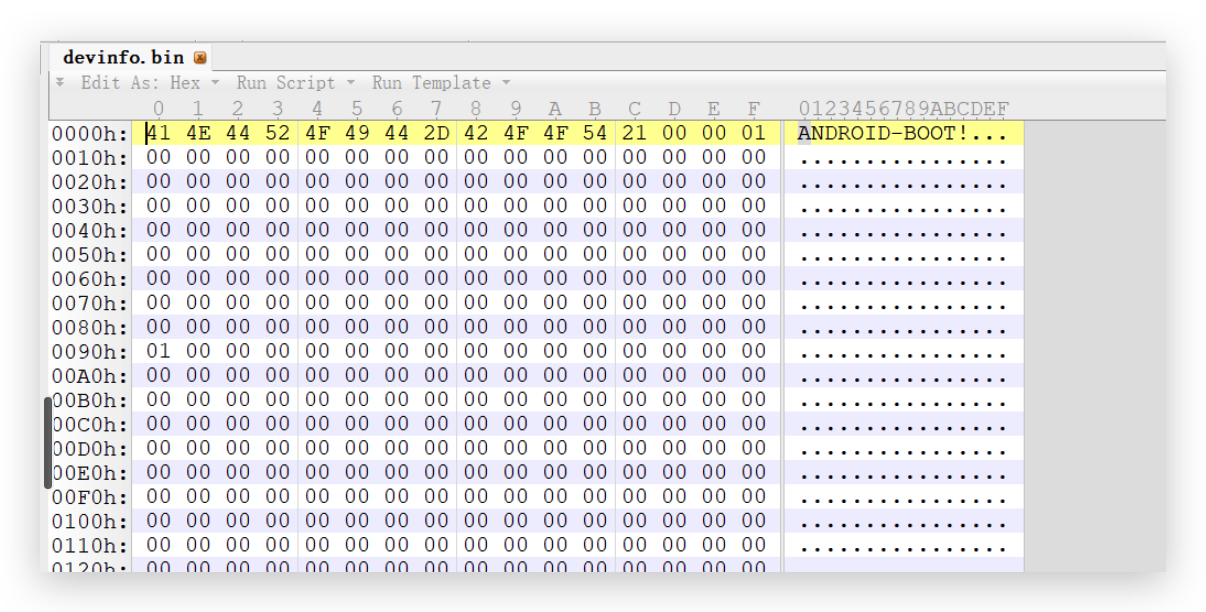
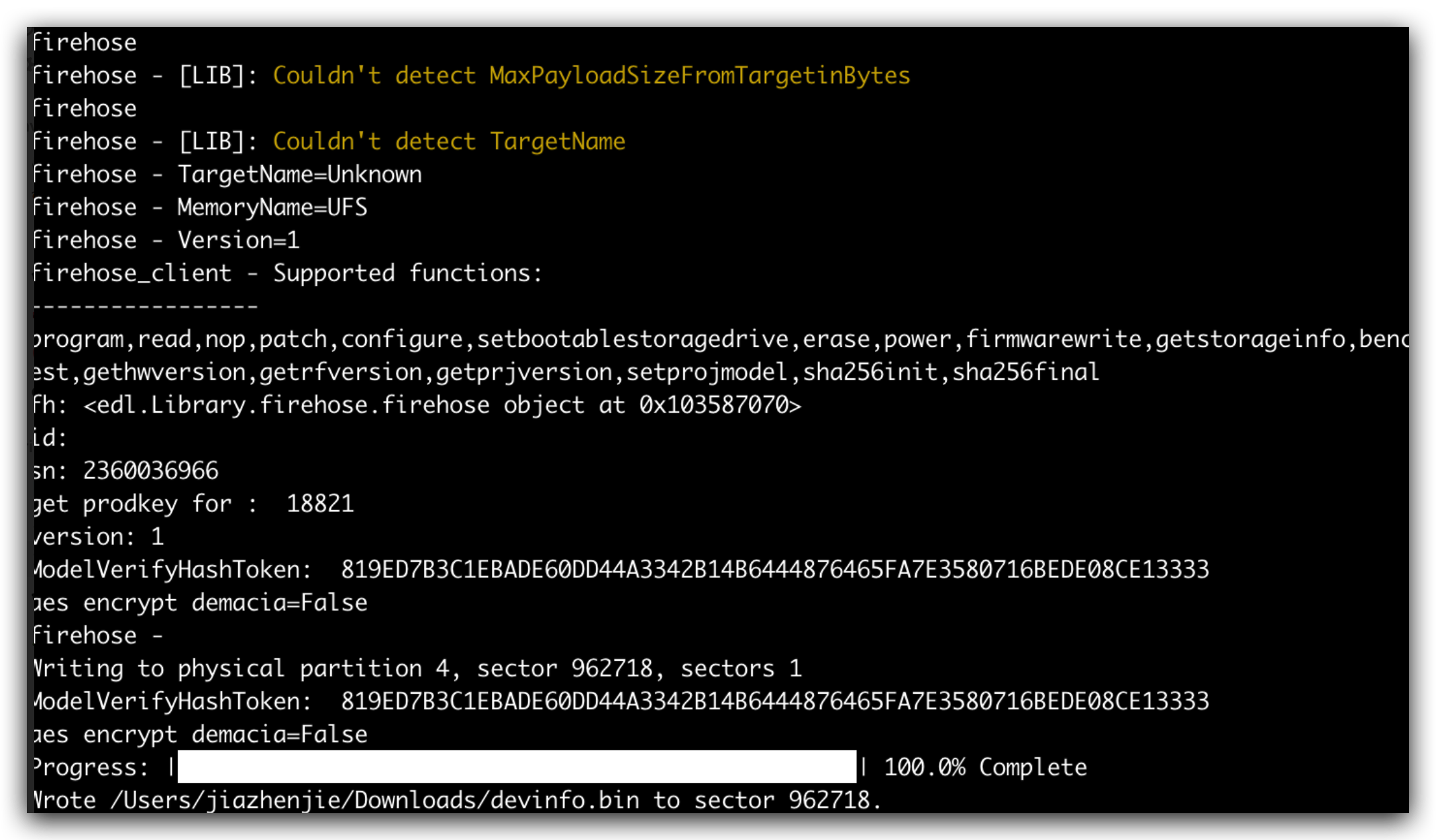
/* We use devinfo partition when the device is not secure */ AsciiStrnCpy((CHAR8 *)img_name, "devinfo", AsciiStrLen("devinfo")); if (convert_char8_to_char16(img_name, img_label, AsciiStrLen("devinfo")) != EFI_SUCCESS) { status = RETURN_INVALID_PARAMETER; gotoexit; }
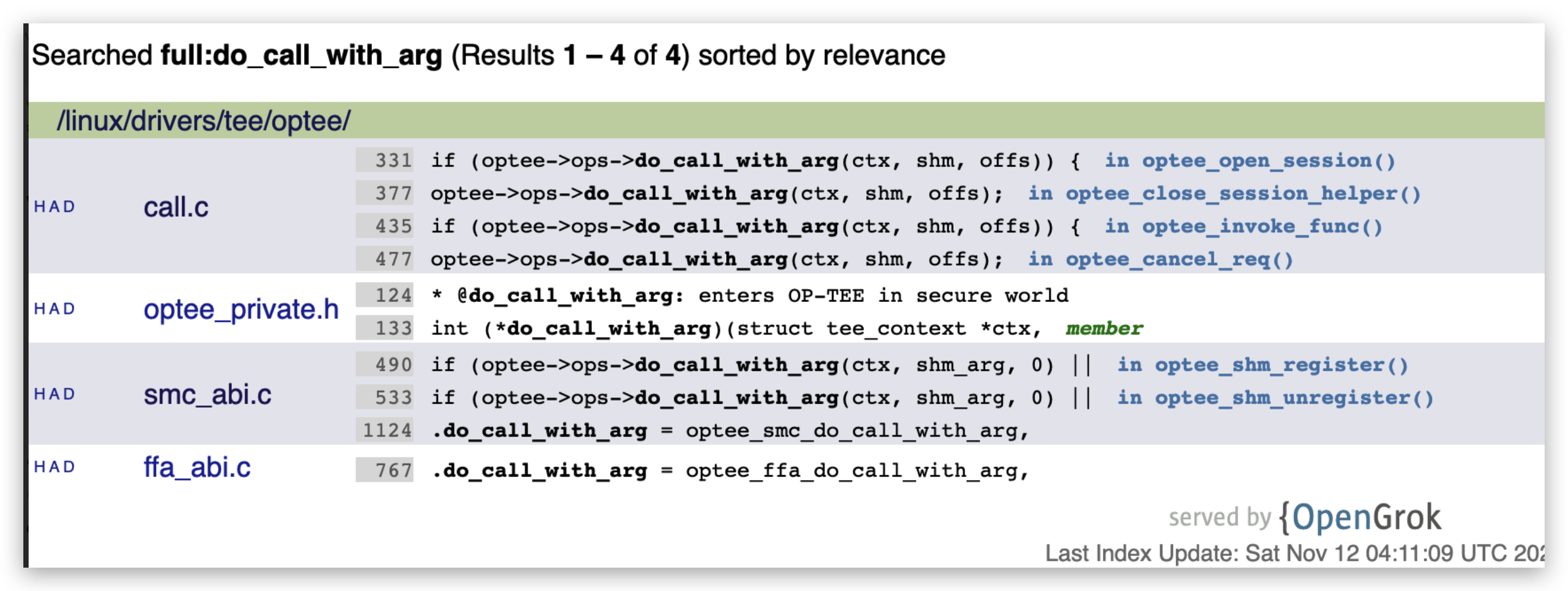
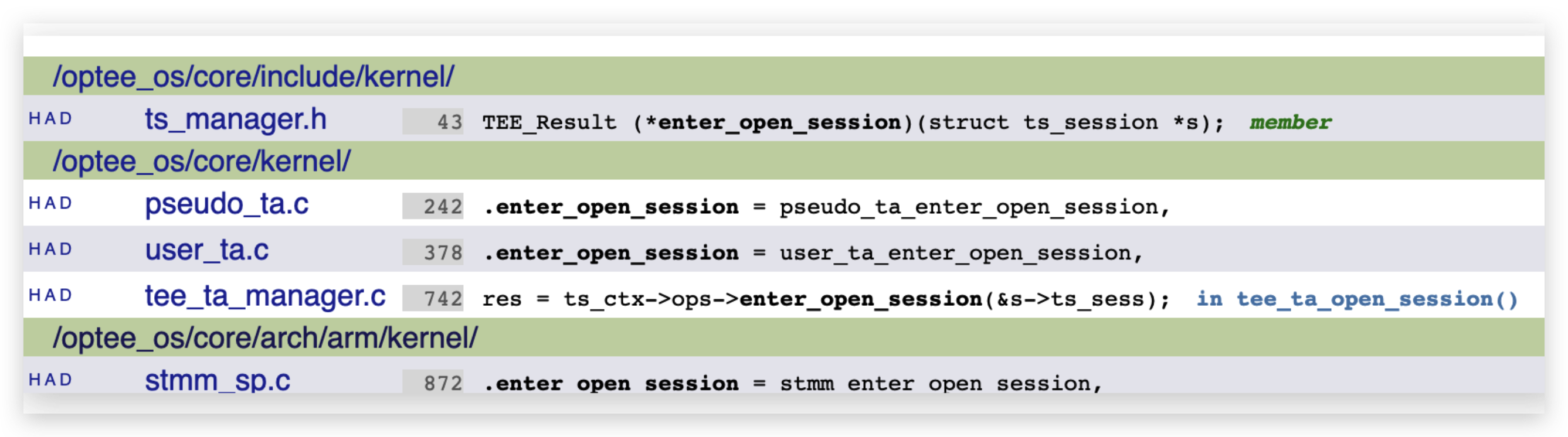
/** * struct optee_ops - OP-TEE driver internal operations * @do_call_with_arg: enters OP-TEE in secure world * @to_msg_param: converts from struct tee_param to OPTEE_MSG parameters * @from_msg_param: converts from OPTEE_MSG parameters to struct tee_param * * These OPs are only supposed to be used internally in the OP-TEE driver * as a way of abstracting the different methogs of entering OP-TEE in * secure world. */ structoptee_ops { int (*do_call_with_arg)(struct tee_context *ctx, struct tee_shm *shm_arg, u_int offs); int (*to_msg_param)(struct optee *optee, struct optee_msg_param *msg_params, size_t num_params, const struct tee_param *params); int (*from_msg_param)(struct optee *optee, struct tee_param *params, size_t num_params, const struct optee_msg_param *msg_params); };
arg.session = session->session_id; if (ioctl(session->ctx->fd, TEE_IOC_CLOSE_SESSION, &arg)) EMSG("Failed to close session 0x%x", session->session_id); }
]]><h2 id="环境"><a href="#环境" class="headerlink" title="环境"></a>环境</h2><ul>
<li> ubuntu22.04 </li>
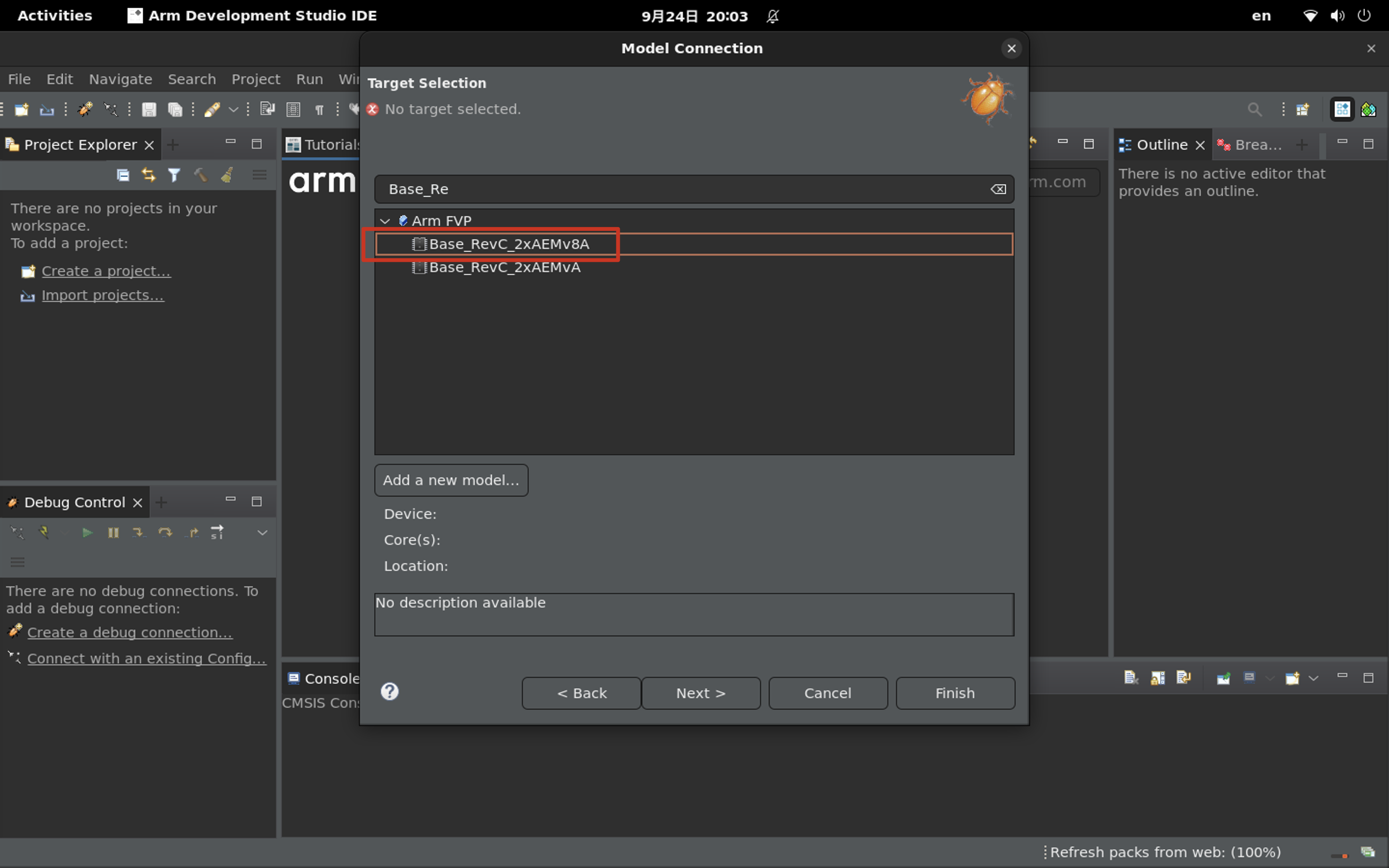
<li> ADS + optee-fvp</li>
</ul>
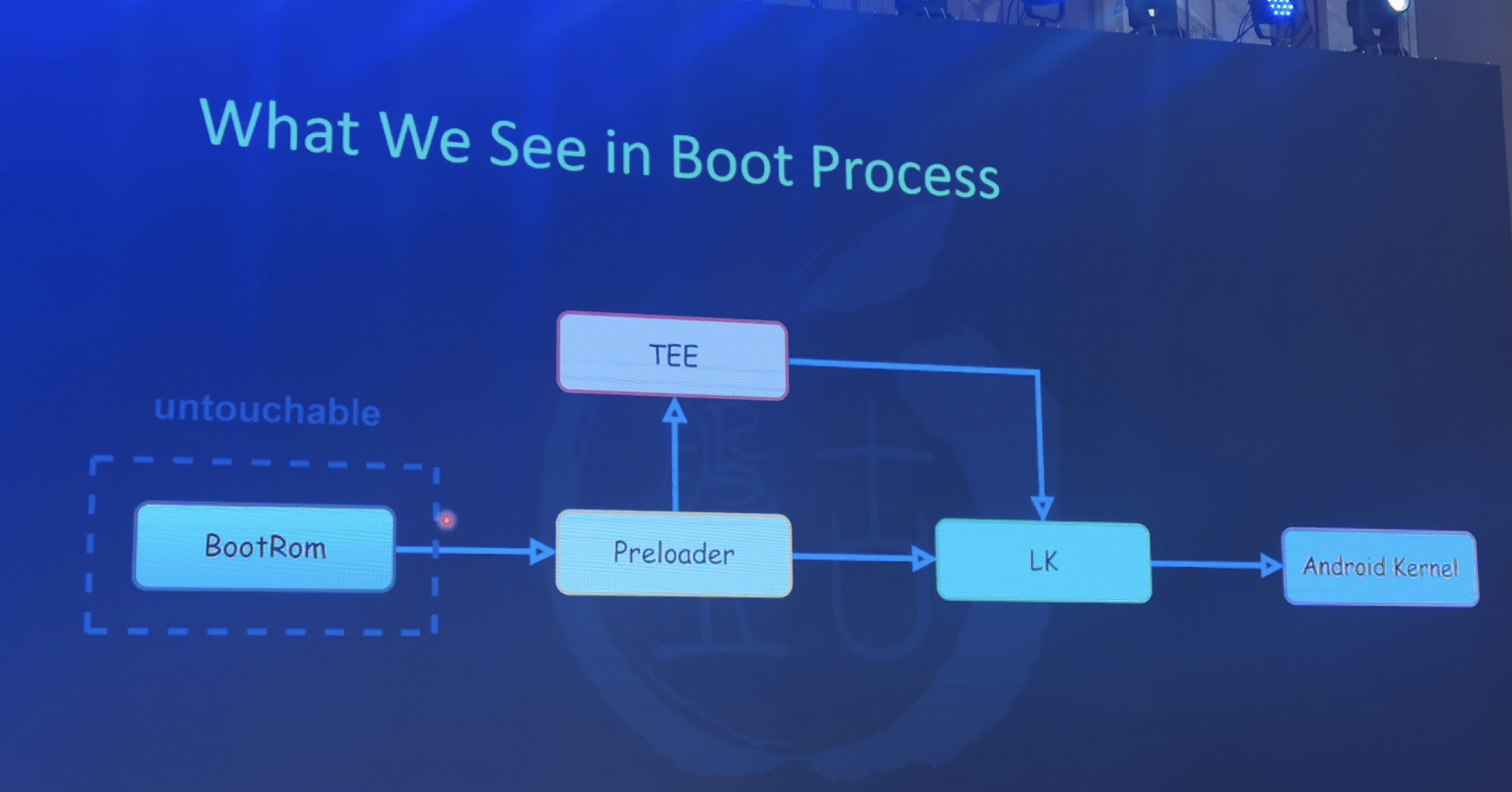
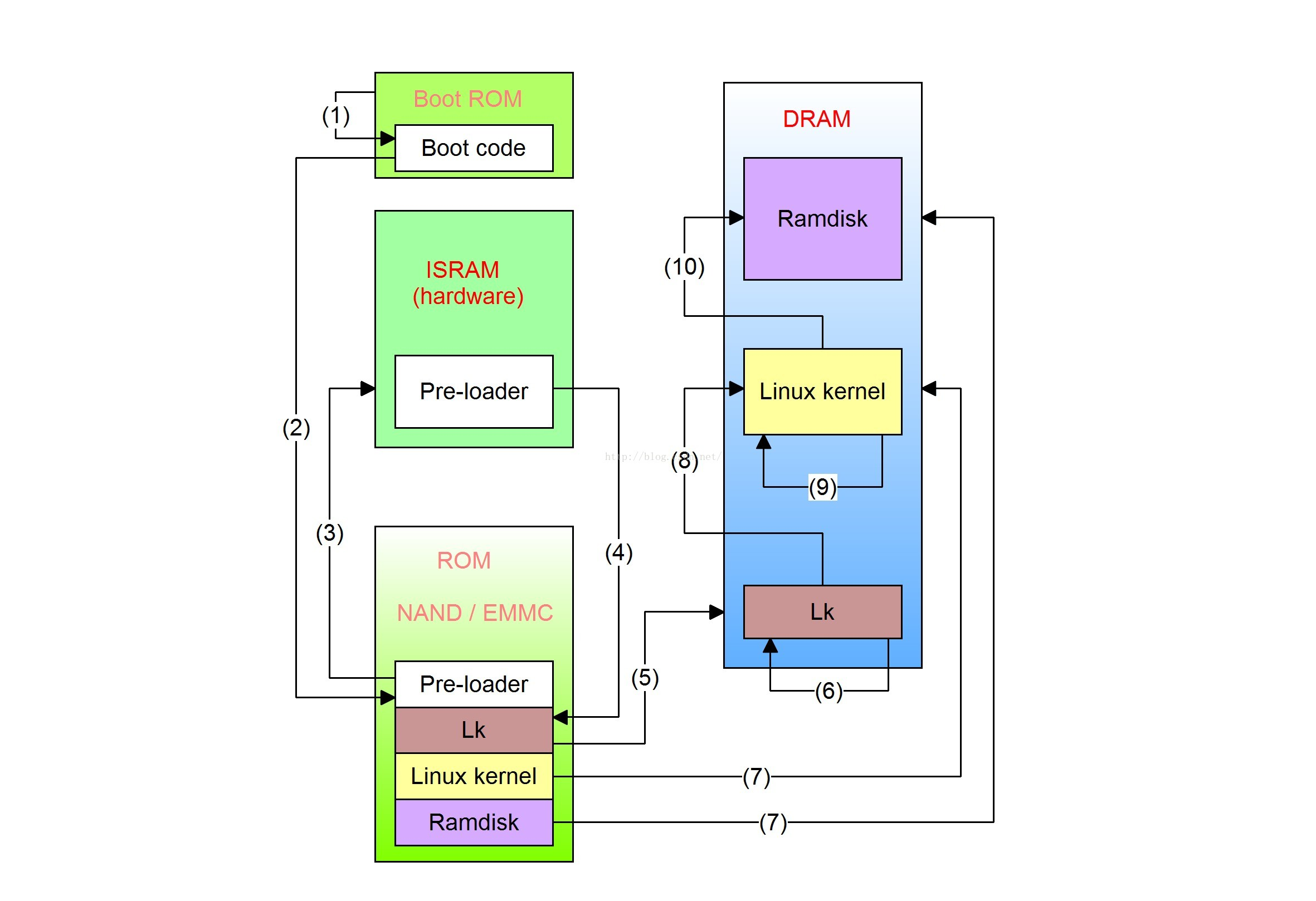
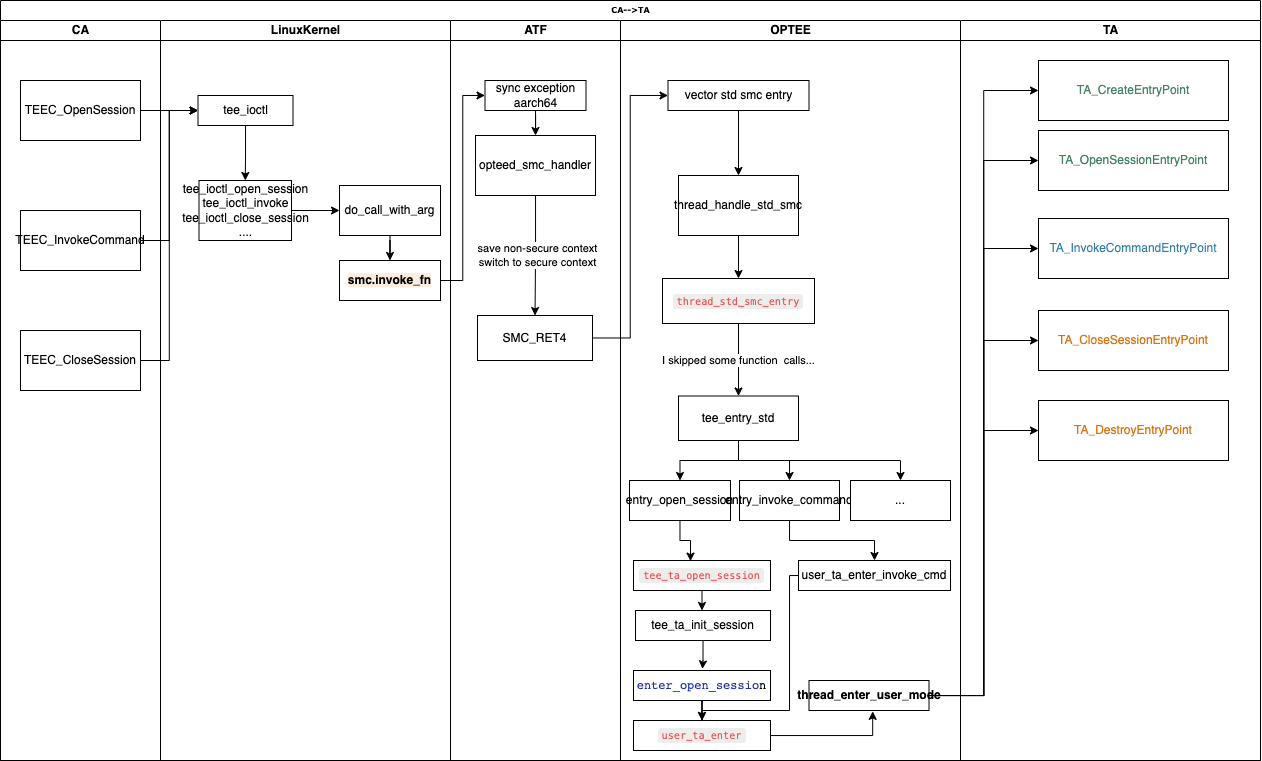
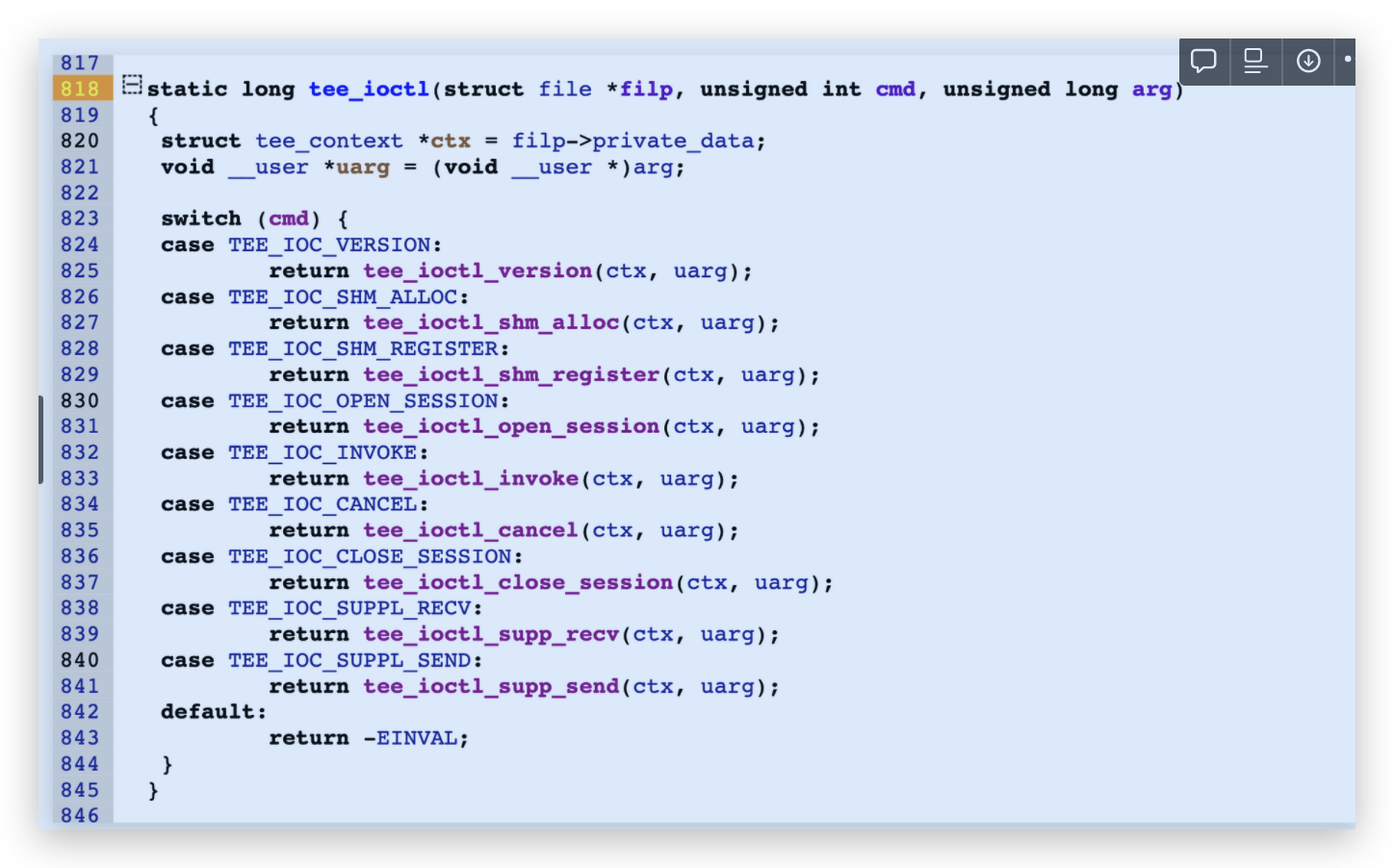
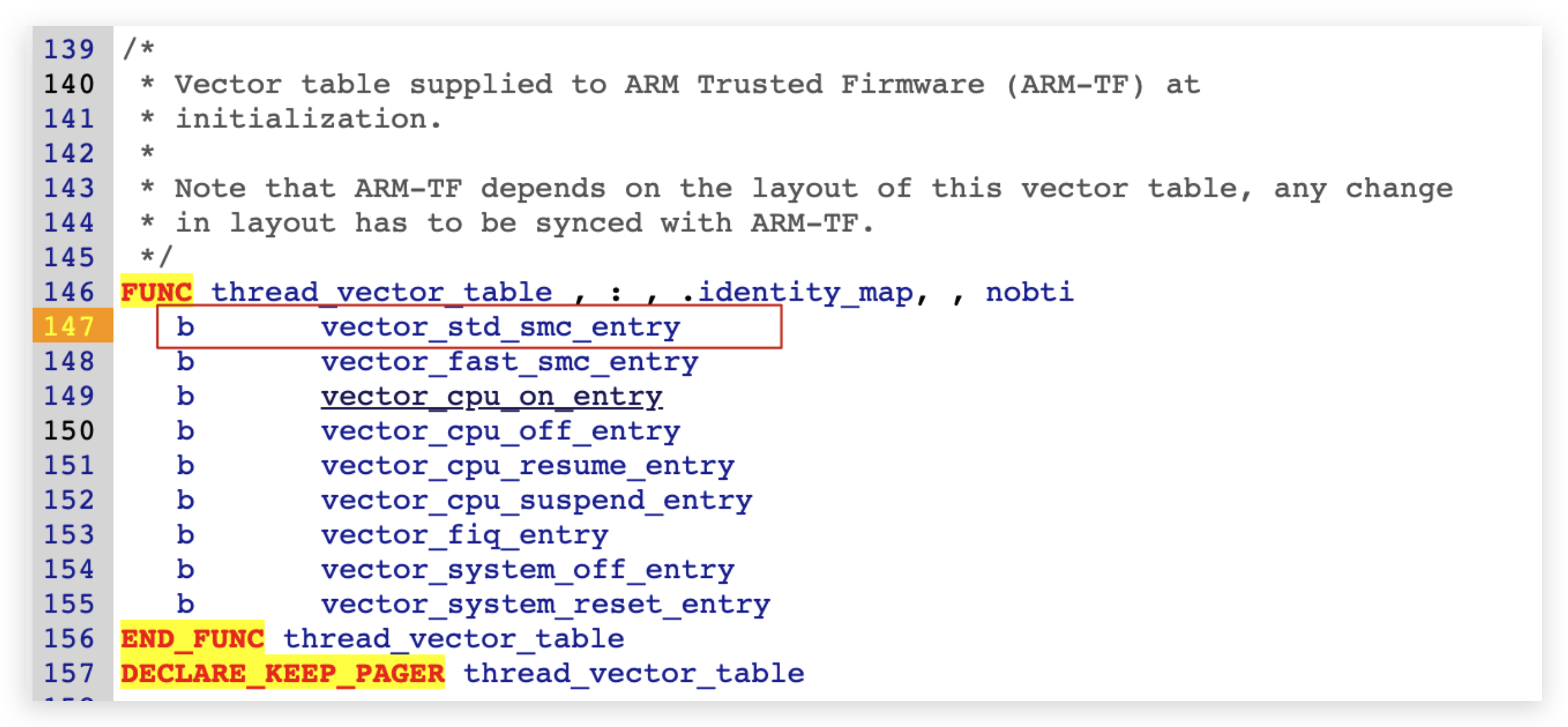
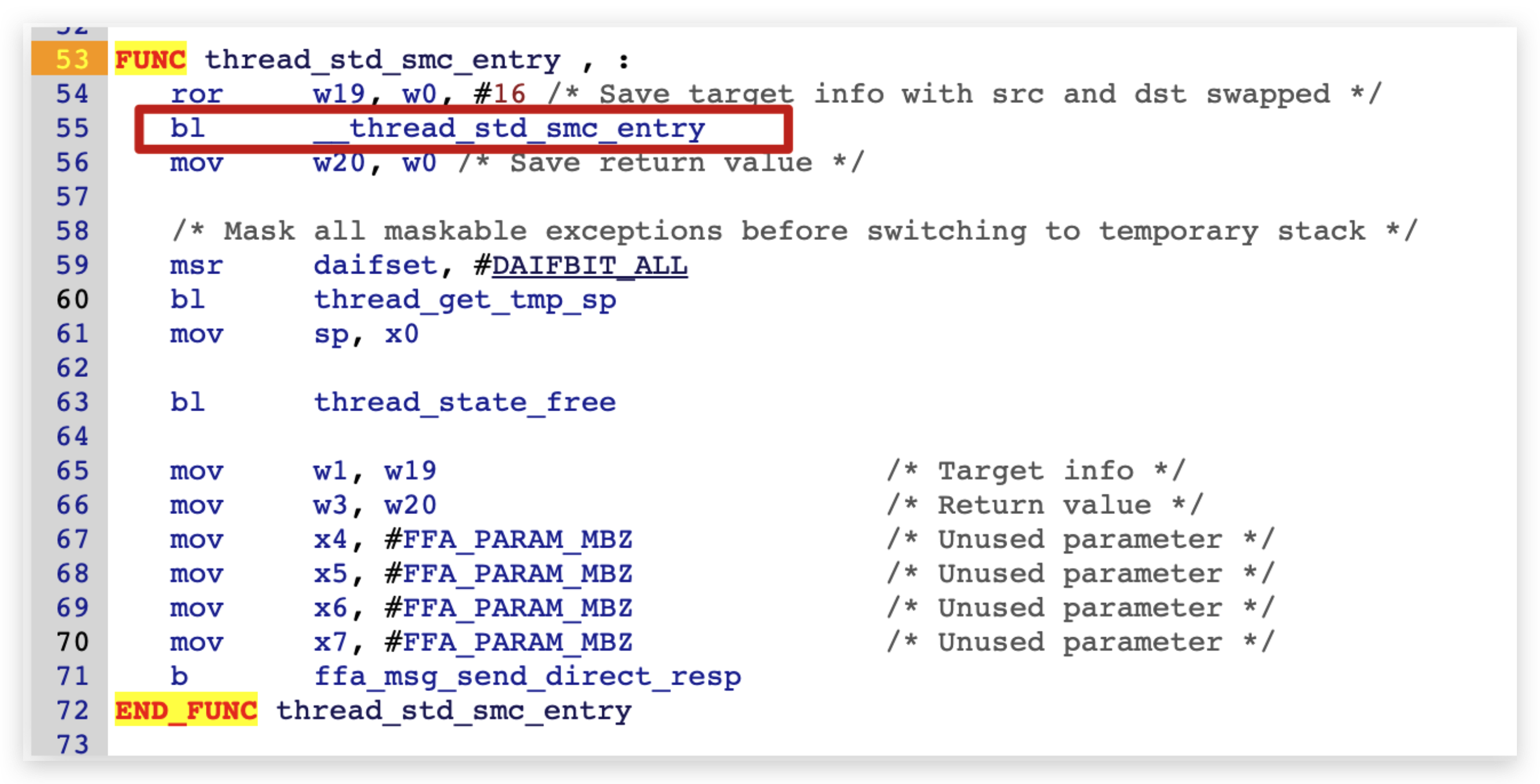
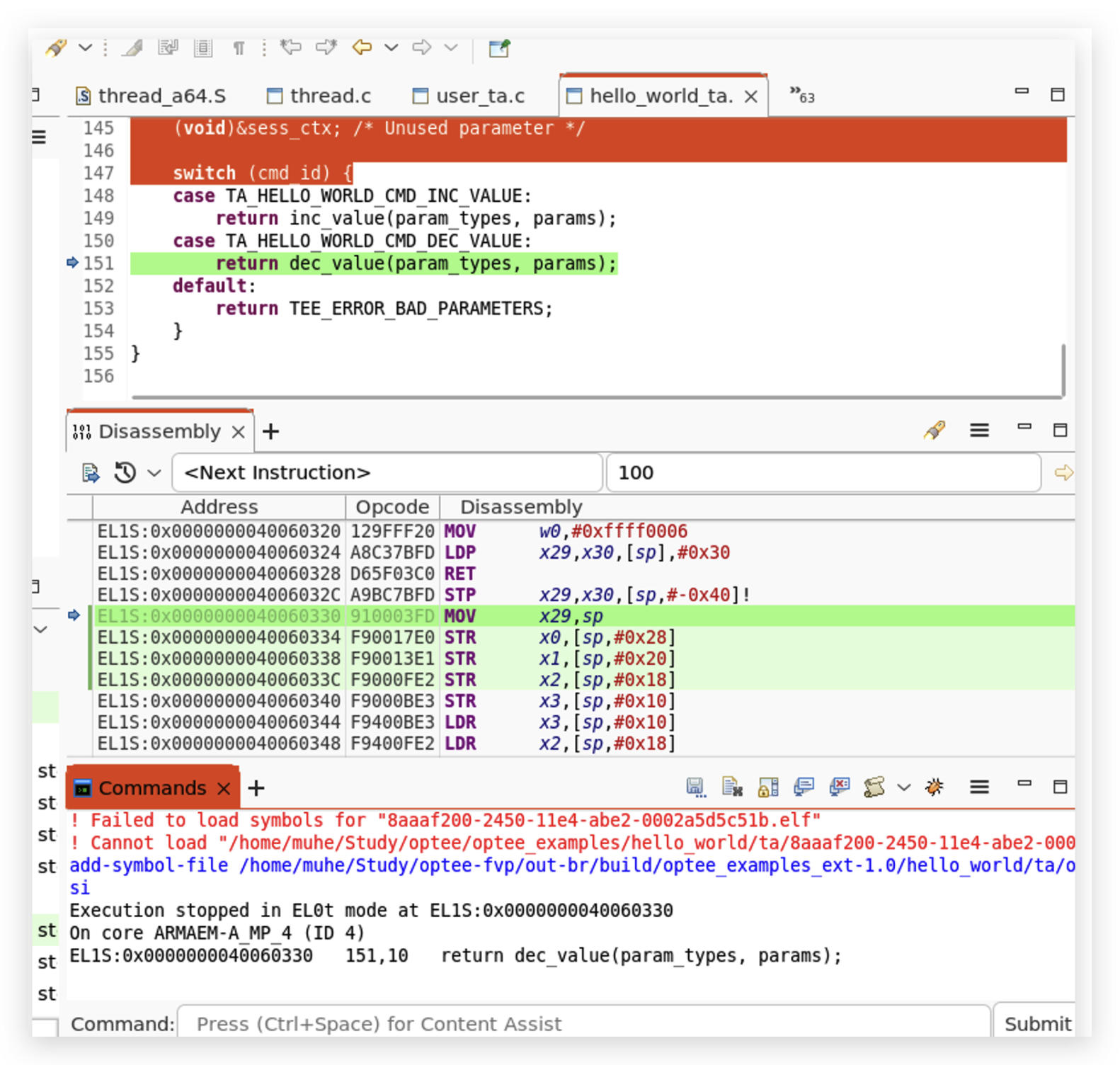
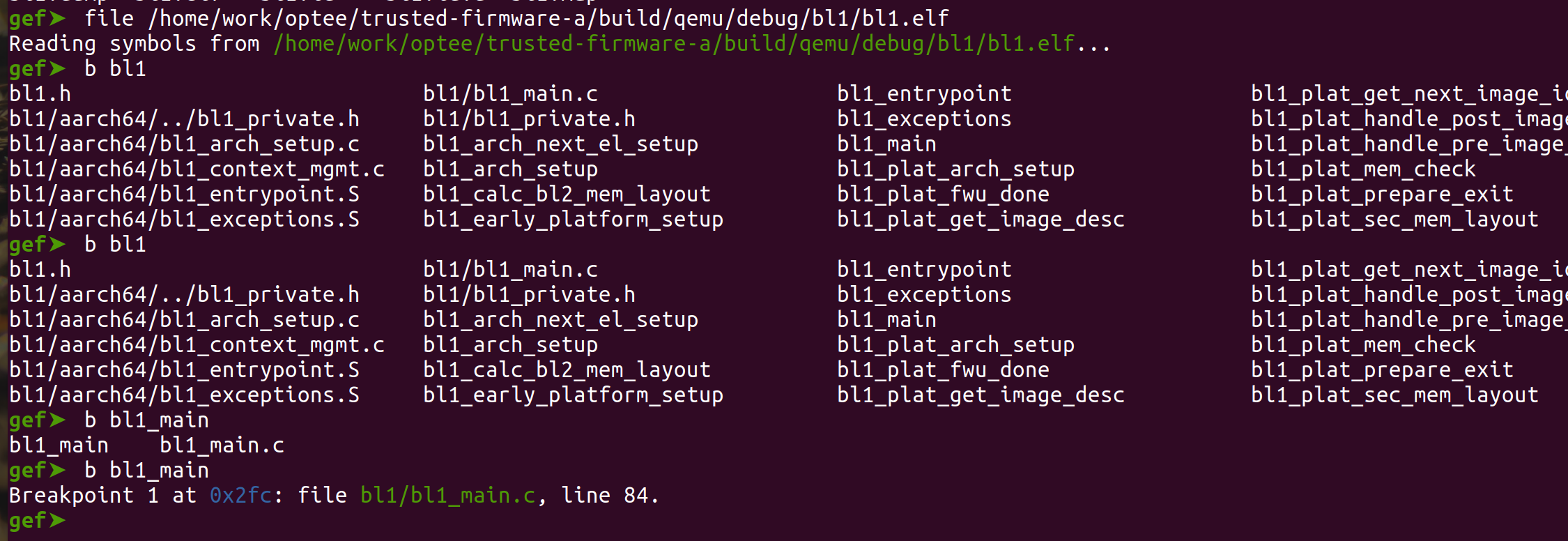
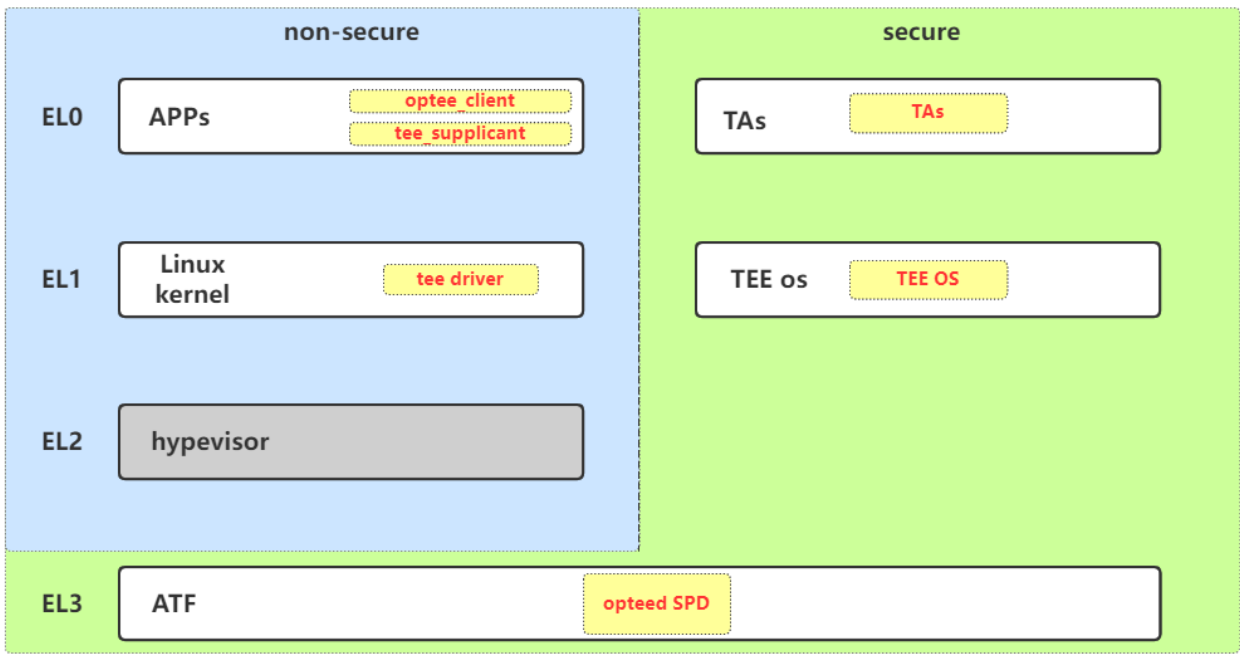
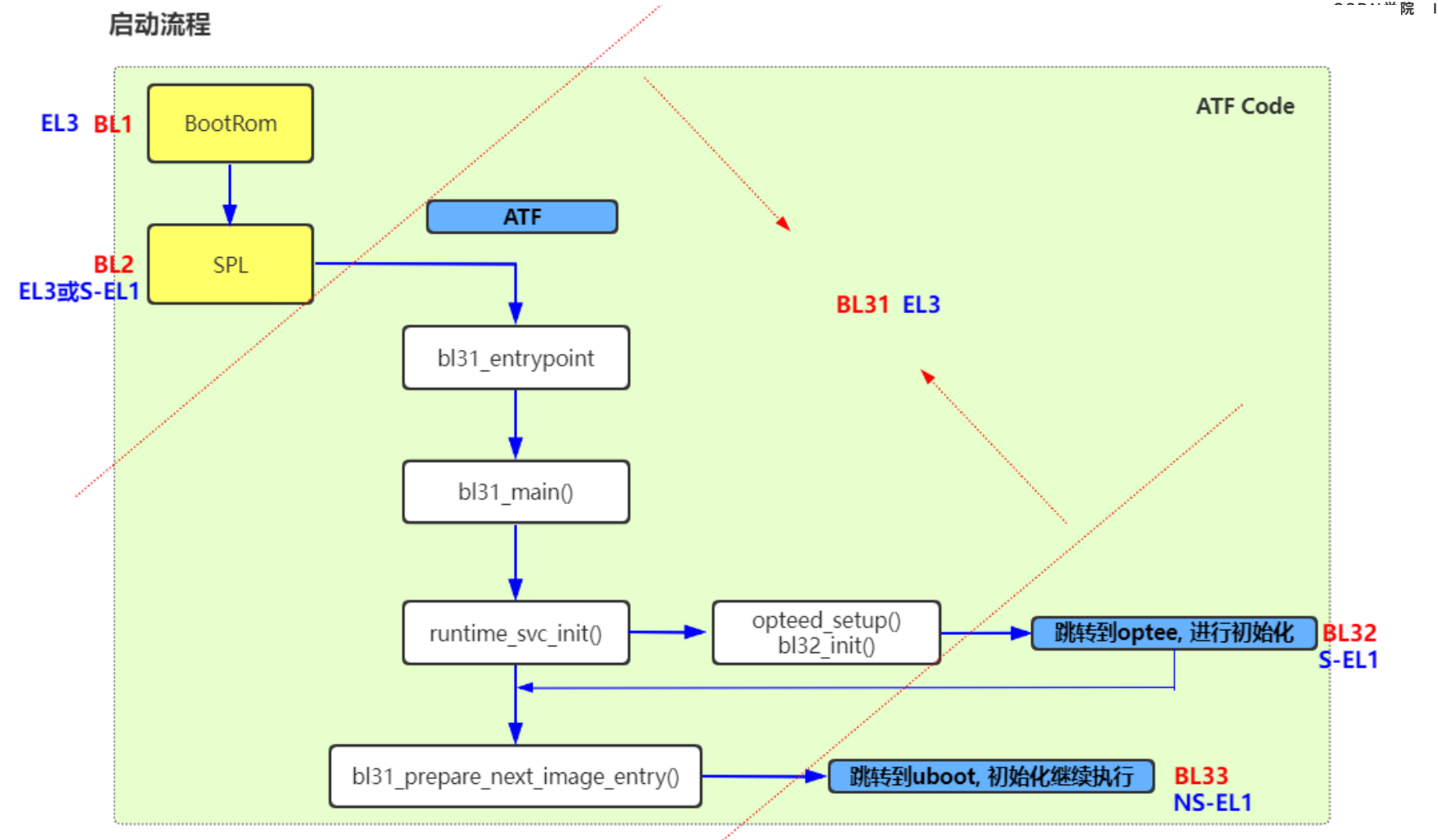
<h2 id="调用流程梳理"><a href="#调用流程梳理" class="headerlink" title="调用流程梳理"></a>调用流程梳理</h2><p> 这里直接从optee-examples中最简单的hello world入手来看的,从宏观上来看整个调用流程是 :</p>
<figure class="highlight plaintext"><table><tr><td class="gutter"><pre><span class="line">1</span><br></pre></td><td class="code"><pre><span class="line">CA --> optee client --> tee driver --> ATF --> TEE --> TA</span><br></pre></td></tr></table></figure>Paper read <<The Convergence of Source Code and Binary Vulnerability Discovery – A Case Study>>https://o0xmuhe.github.io/2022/09/12/Paper-read-The-Convergence-of-Source-Code-and-Binary-Vulnerability-Discovery-%E2%80%93-A-Case-Study/2022-09-12T05:33:26.000Z2022-11-13T07:59:48.027ZBackground
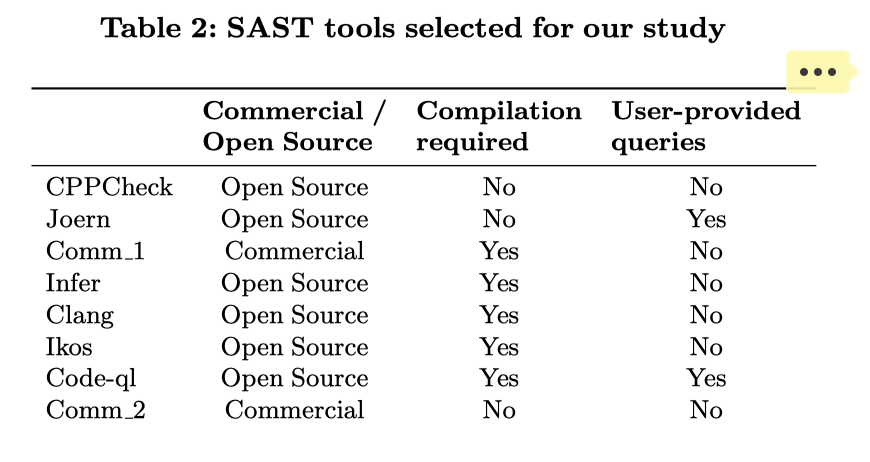
最近阅读了一篇论文<<The Convergence of Source Code and Binary Vulnerability Discovery – A Case Study>>,很巧合的是论文的研究中,关于将SAST工具应用于二进制文件(通过decompiler),即获取伪代码之后,在伪代码上跑SAST工具来找漏洞这个模式我和@C0ss4ck一起做过,在我们收到一些成效之后发现也有人做了类似的工作,不过他好像没有特别深入 :D
decompilers are still designed to generate code that is easy to understand for humans, and SAST tools are still designed to parse “well-written” code that is not generated by a machine.
]]><h2 id="Background"><a href="#Background" class="headerlink" title="Background"></a><code>Background</code></h2><p> 最近阅读了一篇论文<code><<The Convergence of Source Code and Binary Vulnerability Discovery – A Case Study>></code>,很巧合的是论文的研究中,关于将SAST工具应用于二进制文件(通过decompiler),即获取伪代码之后,在伪代码上跑SAST工具来找漏洞这个模式我和<code>@C0ss4ck</code>一起做过,在我们收到一些成效之后发现也有人做了<a href="https://security.humanativaspa.it/automating-binary-vulnerability-discovery-with-ghidra-and-semgrep/">类似的工作</a>,不过他好像没有特别深入 :D </p>HW OTA unpackhttps://o0xmuhe.github.io/2022/09/02/HW-OTA-unpack/2022-09-02T05:43:15.000Z2022-11-13T08:00:43.423Z步骤
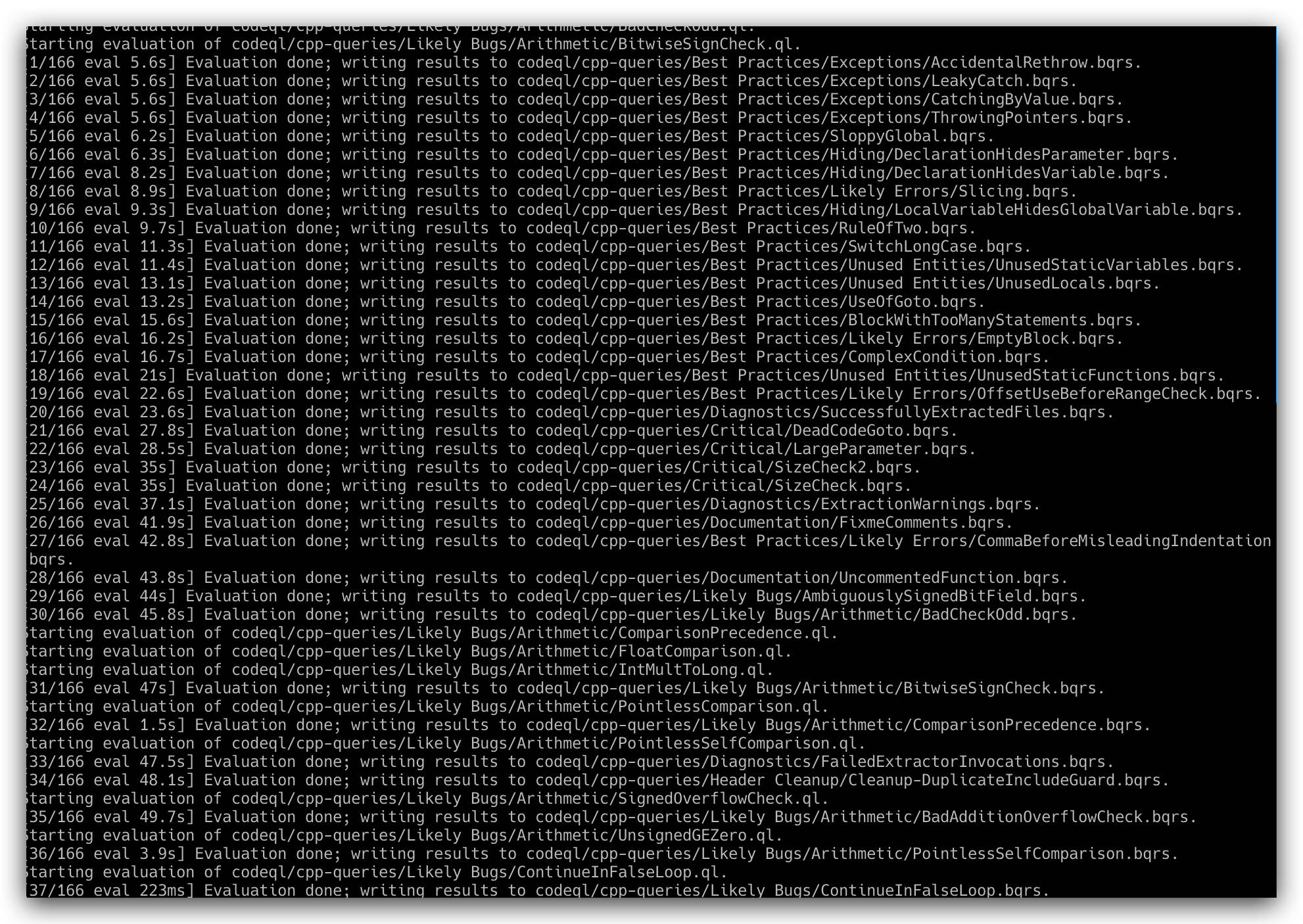
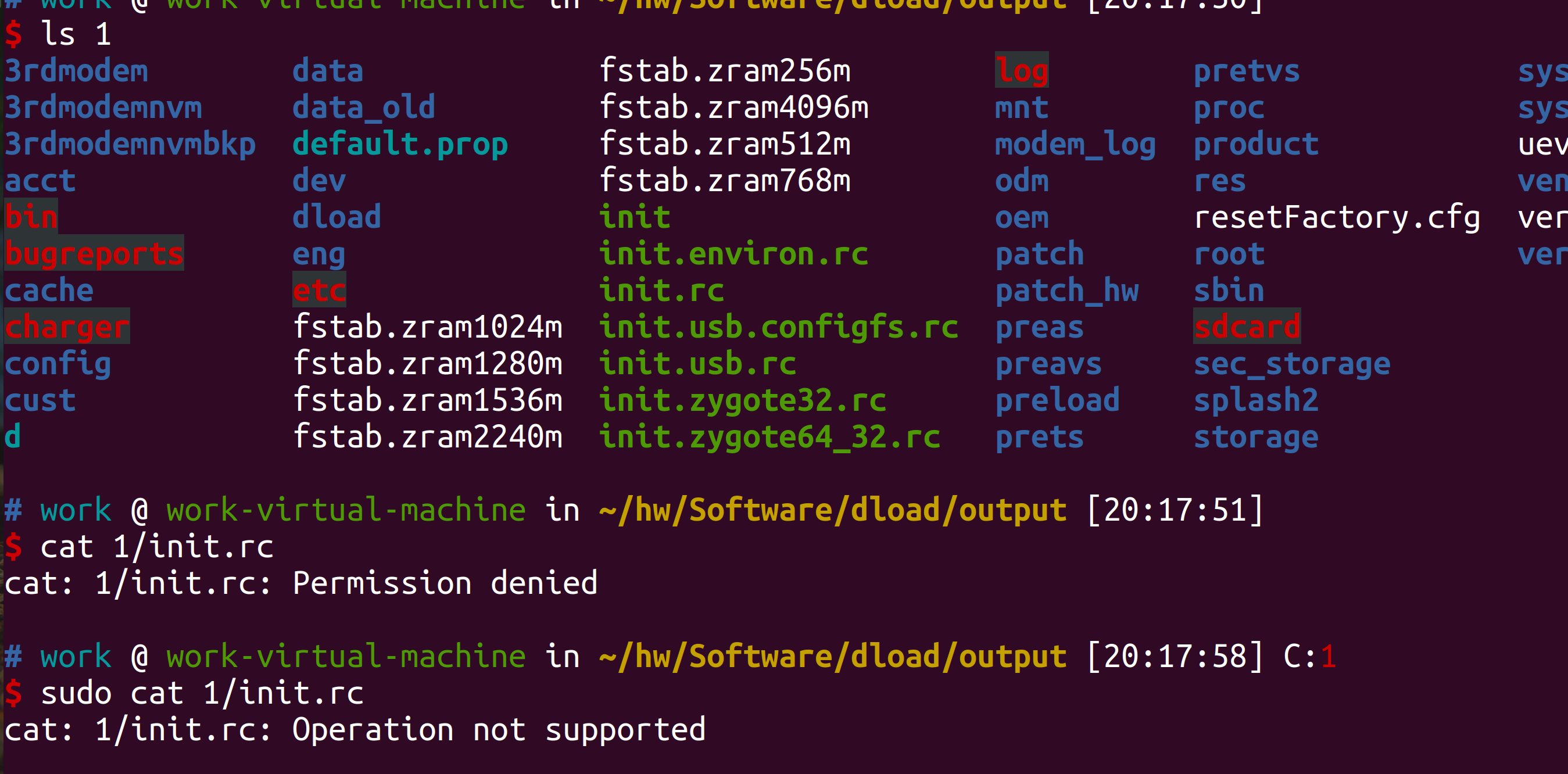
# work @ work-virtual-machine in ~/optee-fvp [23:34:36] $ ls -al total 72 drwxrwxr-x 18 work work 4096 Sep 22 23:32 . drwx------ 70 work work 4096 Sep 22 23:34 .. drwxrwxr-x 10 work work 4096 Sep 22 23:32 Base_RevC_AEMvA_pkg drwxrwxr-x 12 work work 4096 Sep 22 23:26 build drwxrwxr-x 14 work work 4096 Sep 22 23:26 buildroot drwxrwxr-x 50 work work 4096 Sep 22 23:26 edk2 drwxrwxr-x 4 work work 4096 Sep 22 23:26 edk2-platforms drwxrwxr-x 14 work work 4096 Sep 22 23:26 grub drwxr-xr-x 3 work work 4096 Jun 16 10:34 license_terms drwxrwxr-x 24 work work 4096 Sep 22 23:26 linux drwxrwxr-x 14 work work 4096 Sep 22 23:26 mbedtls drwxrwxr-x 5 work work 4096 Sep 22 23:26 ms-tpm-20-ref drwxrwxr-x 9 work work 4096 Sep 22 23:26 optee_client drwxrwxr-x 10 work work 4096 Sep 22 23:26 optee_examples drwxrwxr-x 10 work work 4096 Sep 22 23:26 optee_os drwxrwxr-x 7 work work 4096 Sep 22 23:26 optee_test drwxrwxr-x 7 work work 4096 Sep 22 23:26 .repo drwxrwxr-x 19 work work 4096 Sep 22 23:26 trusted-firmware-a
编译
编译流程参考上面qemu_v8部分
1 2 3 4 5
# work @ work-virtual-machine in ~/optee-fvp [23:35:06] $ cp -rf Base_RevC_AEMvA_pkg Foundation_Platformpkg # build toolchains的时候文件夹名需要改一下 $ cd build $ make toolchains $ make DEBUG=1 FVP_USE_BASE_PLAT=y -f fvp.mk all
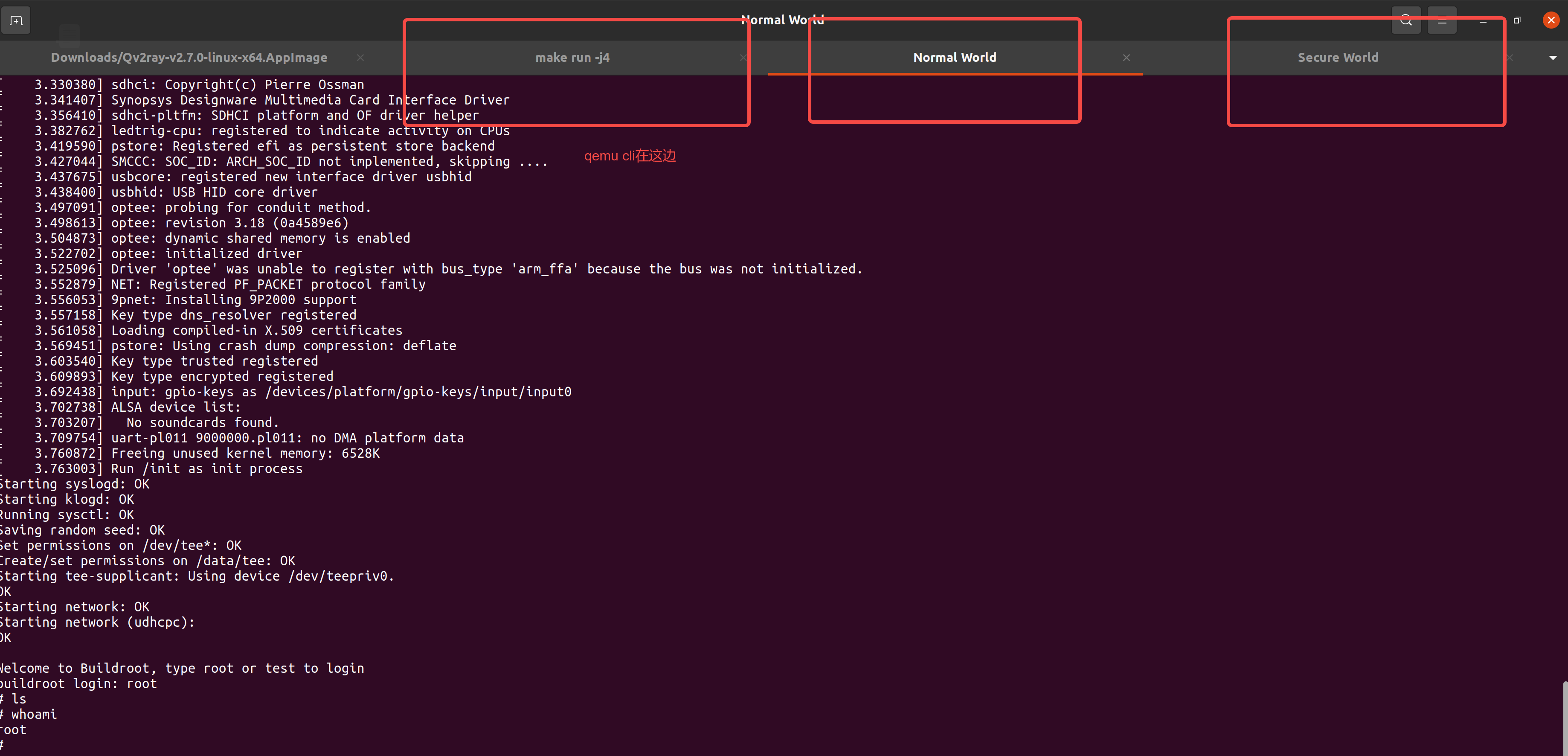
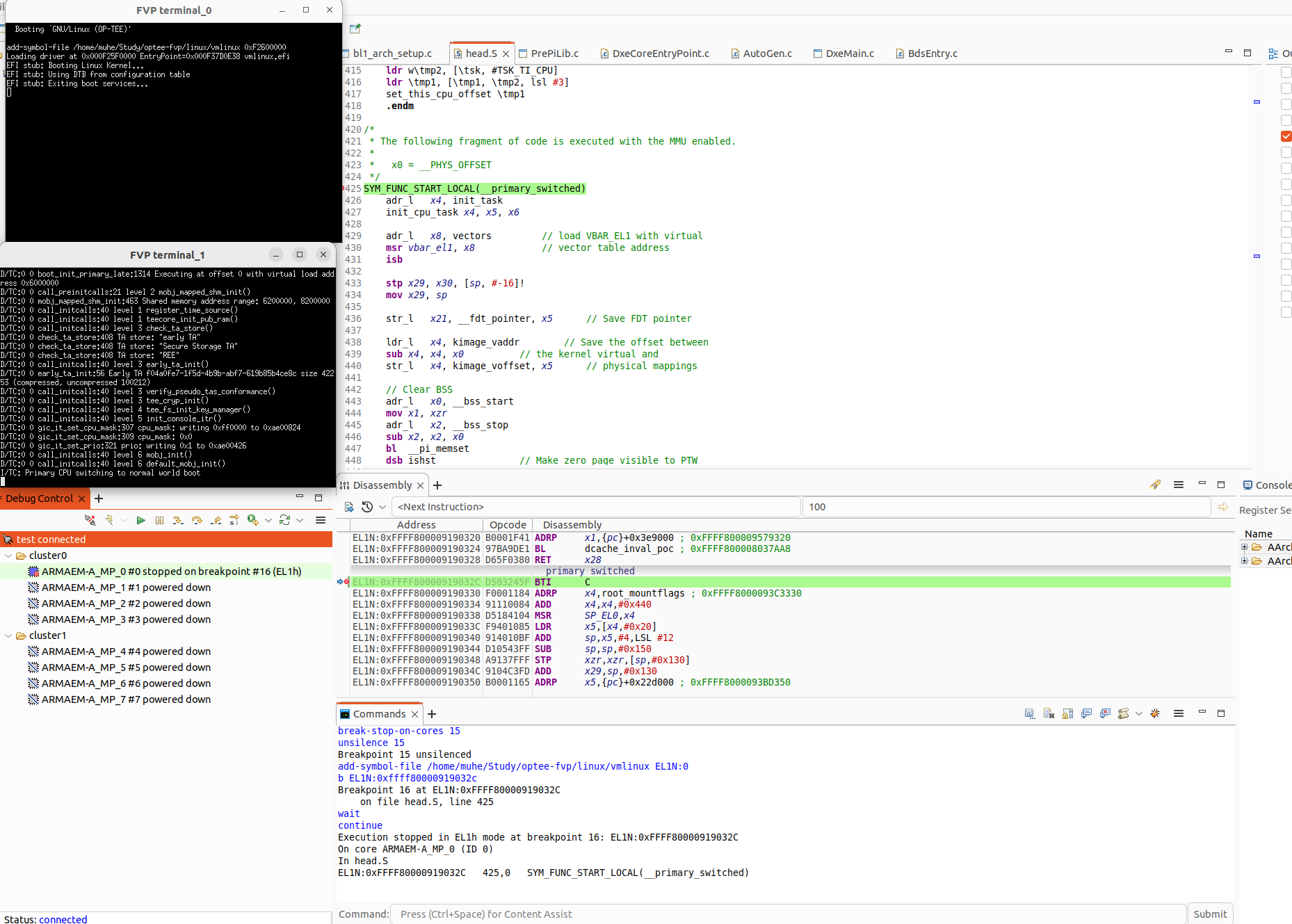
开启调试
修改build/fvp.mk ,以便启动时进入调试模式
添加:
1 2
-I \ --iris-allow-remote\
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
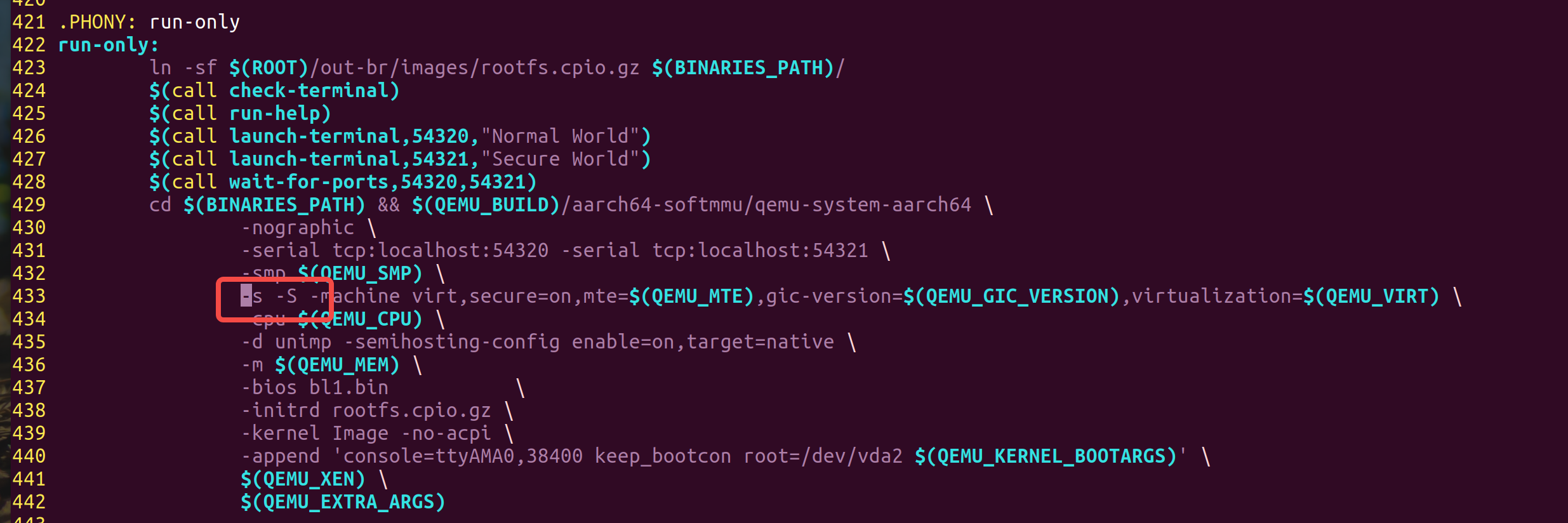
################################################################################ # Run targets ################################################################################ # This target enforces updating root fs etc run: all $(MAKE) run-only
# System Memory(2GB - 16MB of Trusted DRAM at the top of the 32bit address space) gArmTokenSpaceGuid.PcdSystemMemoryBase|0x80000000 gArmTokenSpaceGuid.PcdSystemMemorySize|0x7F000000
BaseAddress = 0x08000000|gArmTokenSpaceGuid.PcdFdBaseAddress # The base address of the Firmware in Flash0.
!else
BaseAddress = 0x88000000|gArmTokenSpaceGuid.PcdFdBaseAddress # UEFI in DRAM + 128MB.
!endif
Size = 0x04000000|gArmTokenSpaceGuid.PcdFdSize # The size in bytes of the device (64MiB).
ErasePolarity = 1
bl33
UEFI
b *EL2N:0x88000000
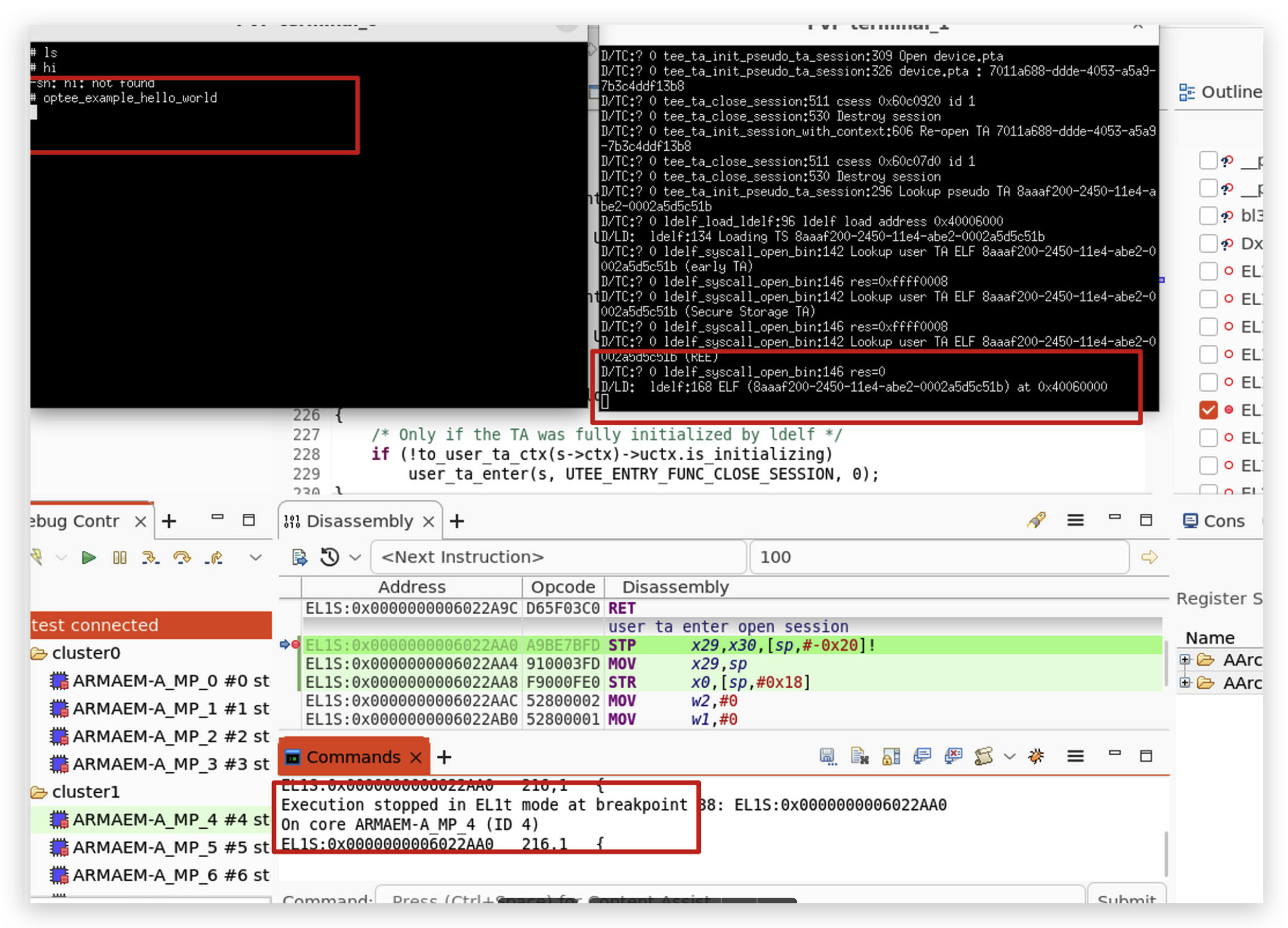
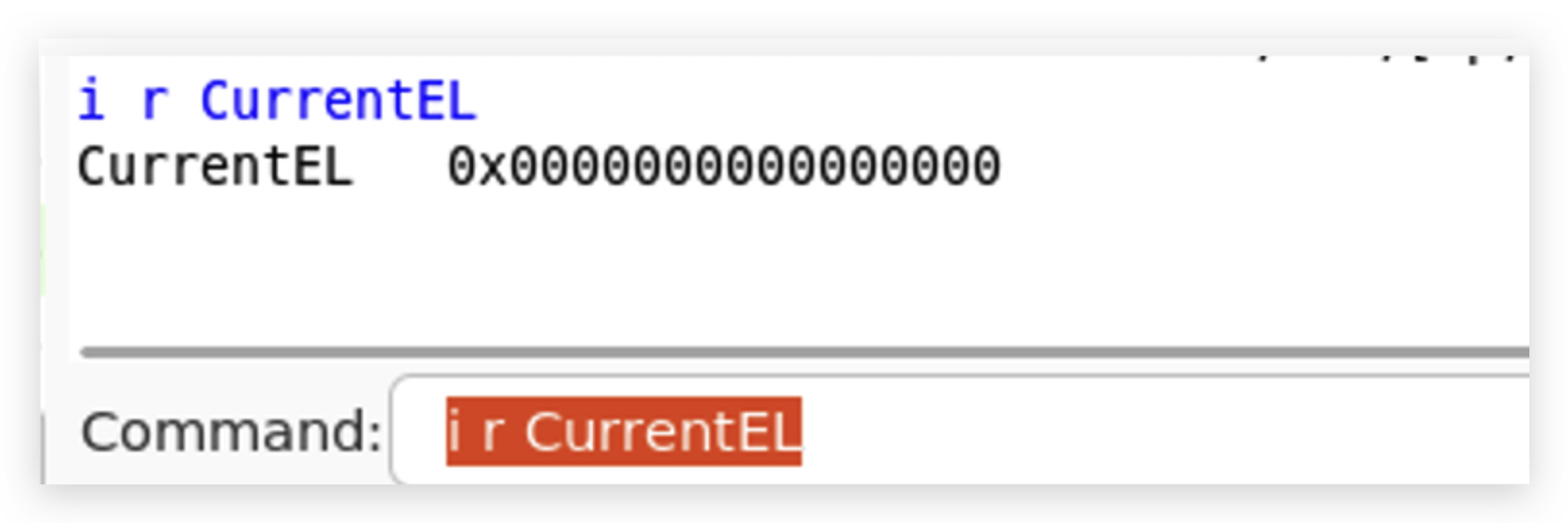
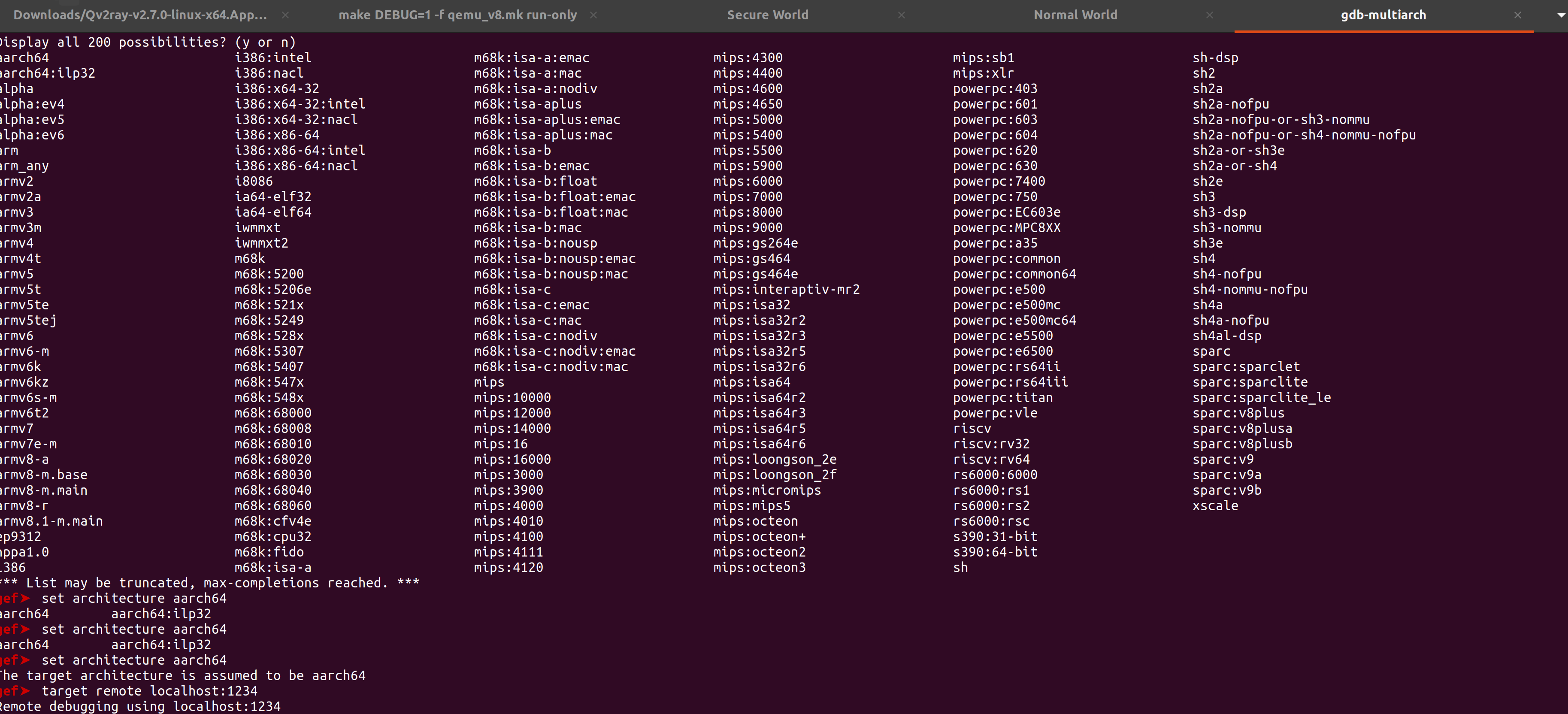
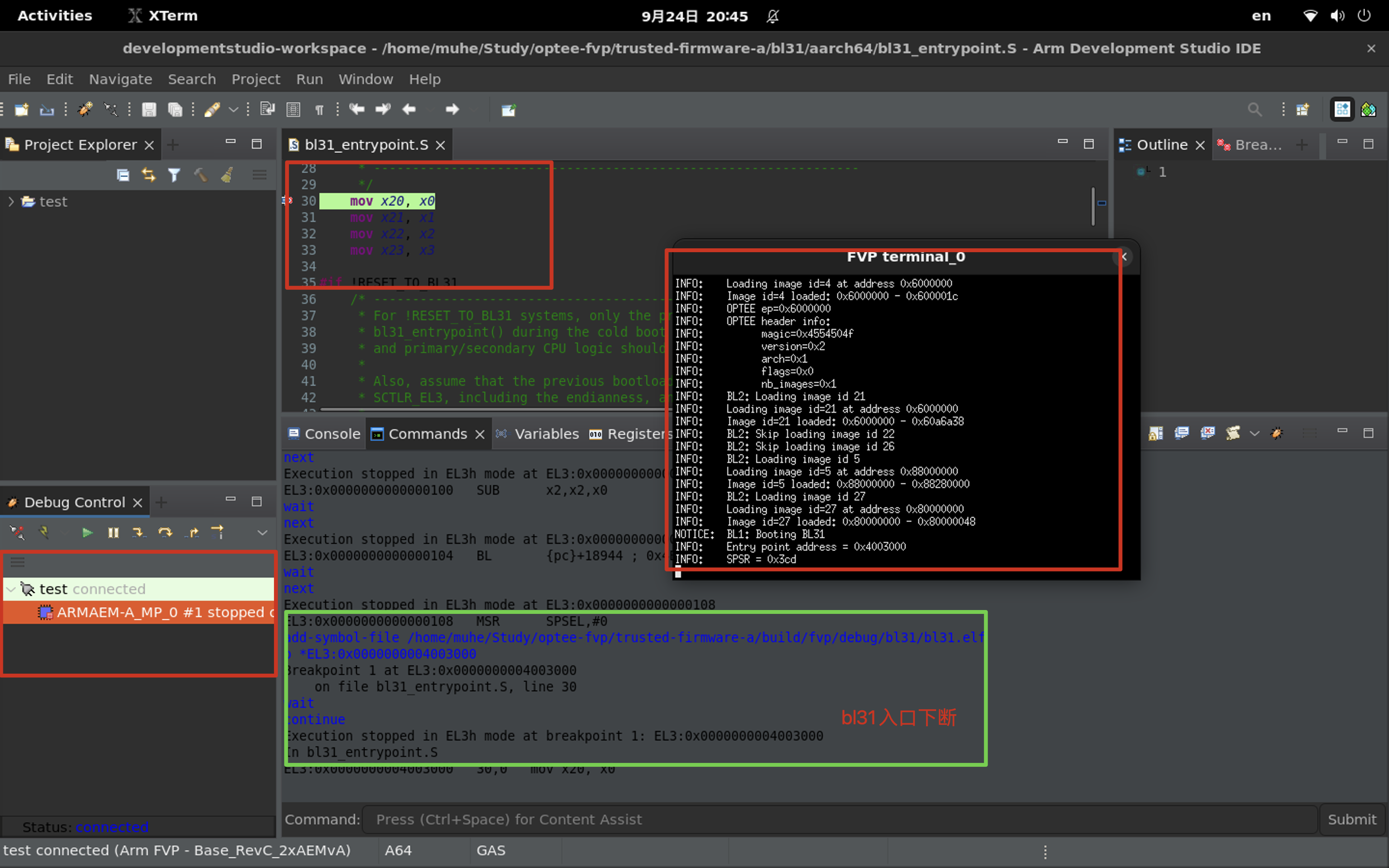
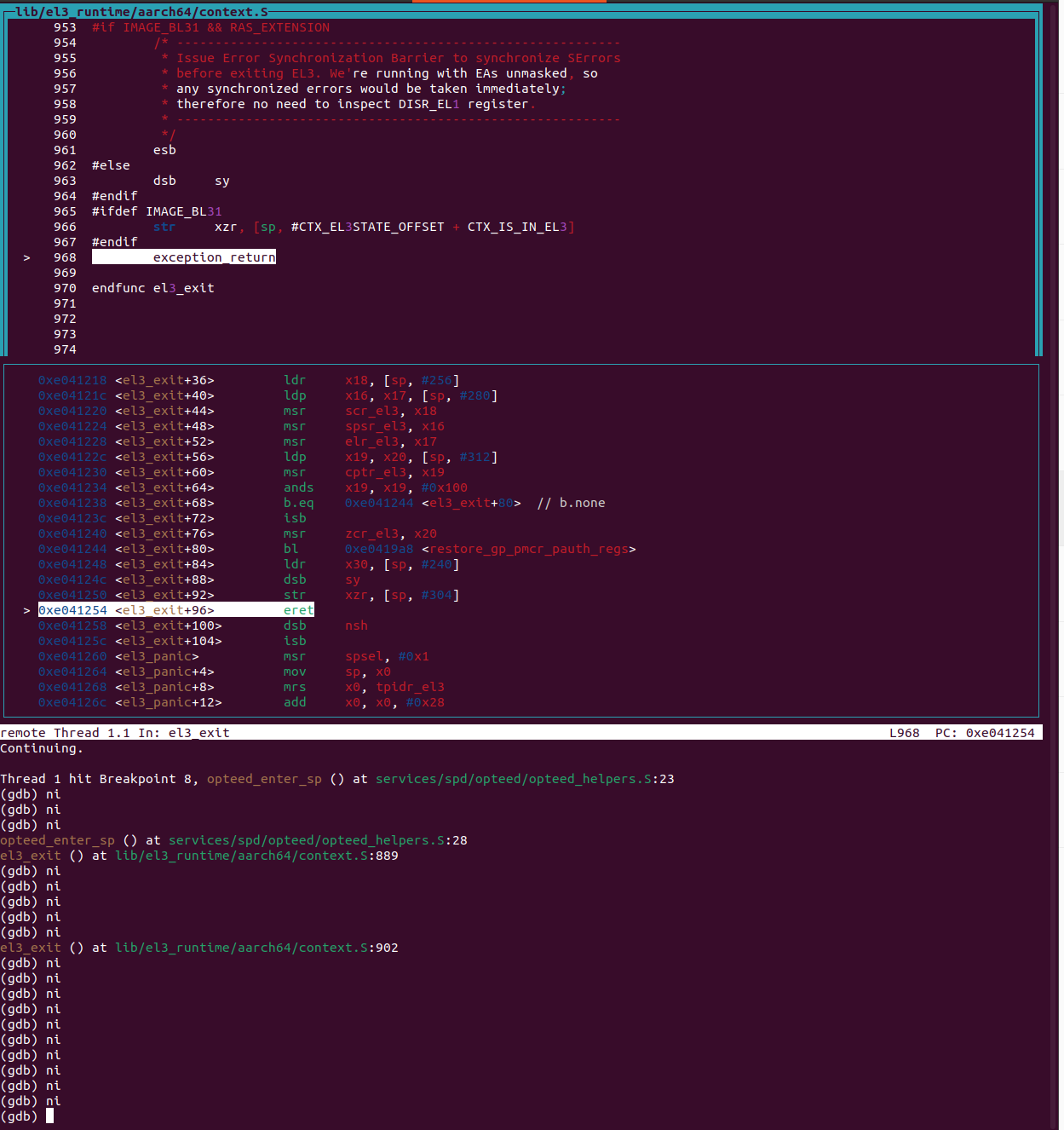
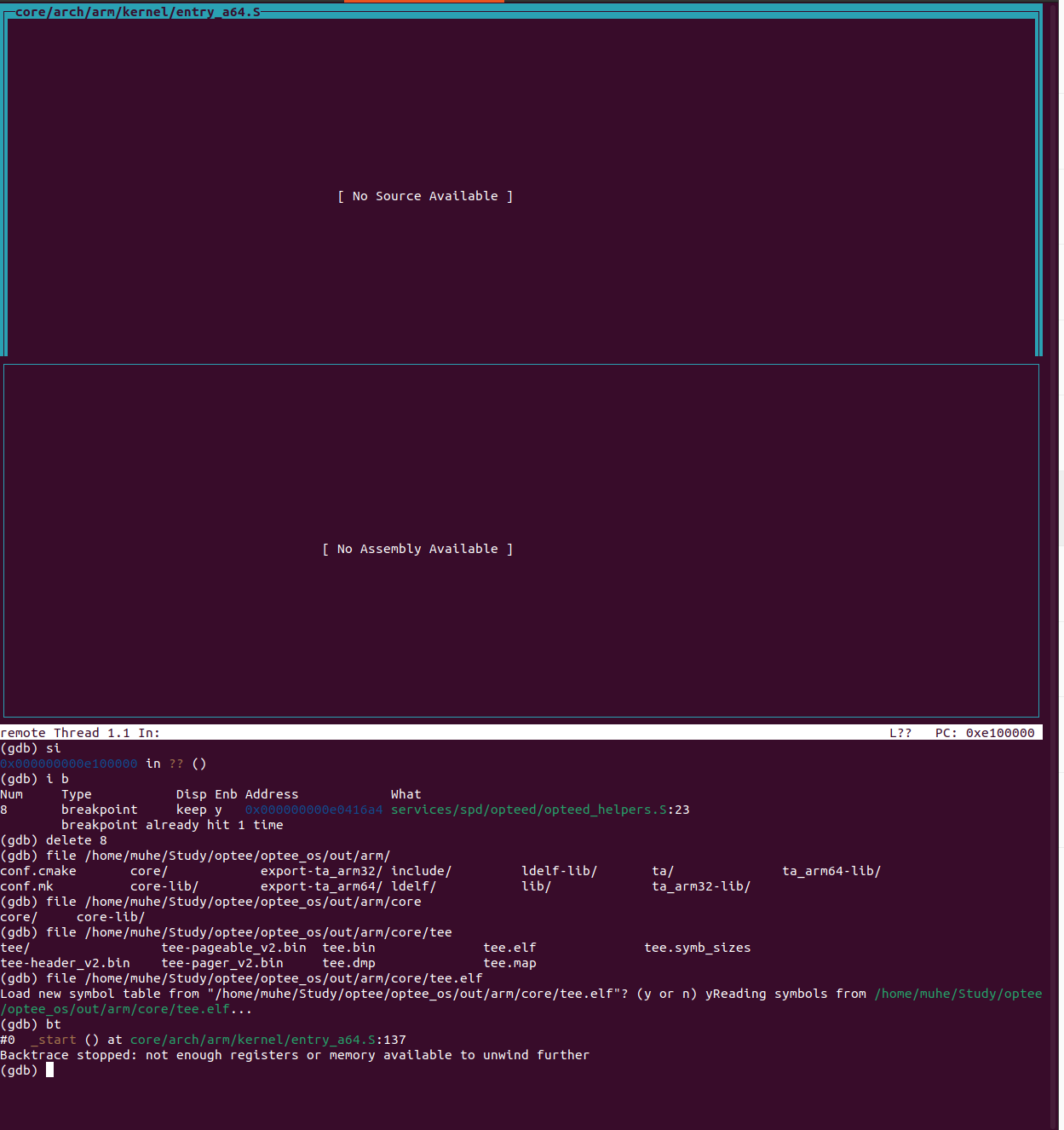
断点触发后, 执行下面的命令加载符号。
1
source /home/muhe/Study/optee-fvp/edk2/ArmPlatformPkg/Scripts/Ds5/cmd_load_symbols.py -a -m (0x80000000, 0x7F000000) -f (0x88000000, 0x04000000)
1 2 3 4 5 6 7 8
info files Symbols from "/home/muhe/Study/optee-fvp/edk2-platforms/Build/ArmVExpress-FVP-AArch64/DEBUG_GCC49/AARCH64/ArmPlatformPkg/PrePi/PeiUniCore/DEBUG/ArmPlatformPrePiUniCore.dll". Local exec file: "/home/muhe/Study/optee-fvp/edk2-platforms/Build/ArmVExpress-FVP-AArch64/DEBUG_GCC49/AARCH64/ArmPlatformPkg/PrePi/PeiUniCore/DEBUG/ArmPlatformPrePiUniCore.dll", file type ELF64. Entry point: EL2N:0x0000000088000800. EL2N:0x0000000088000800 - EL2N:0x0000000088018AD7 is .text EL2N:0x0000000088019000 - EL2N:0x000000008801916F is .data
Symbols from "/home/muhe/Study/optee-fvp/edk2-platforms/Build/ArmVExpress-FVP-AArch64/DEBUG_GCC49/AARCH64/ArmPlatformPkg/PrePi/PeiUniCore/DEBUG/ArmPlatformPrePiUniCore.dll". Local exec file: "/home/muhe/Study/optee-fvp/edk2-platforms/Build/ArmVExpress-FVP-AArch64/DEBUG_GCC49/AARCH64/ArmPlatformPkg/PrePi/PeiUniCore/DEBUG/ArmPlatformPrePiUniCore.dll", file type ELF64. Entry point: EL2N:0x0000000088000800. EL2N:0x0000000088000800 - EL2N:0x0000000088018AD7 is .text EL2N:0x0000000088019000 - EL2N:0x000000008801916F is .data Symbols from "/home/muhe/Study/optee-fvp/edk2-platforms/Build/ArmVExpress-FVP-AArch64/DEBUG_GCC49/AARCH64/MdeModulePkg/Core/Dxe/DxeMain/DEBUG/DxeCore.dll". Local exec file: "/home/muhe/Study/optee-fvp/edk2-platforms/Build/ArmVExpress-FVP-AArch64/DEBUG_GCC49/AARCH64/MdeModulePkg/Core/Dxe/DxeMain/DEBUG/DxeCore.dll", file type ELF64. Entry point: EL2N:0x00000000FE3D4000. EL2N:0x00000000FE3D4000 - EL2N:0x00000000FE41AEBF is .text EL2N:0x00000000FE41B000 - EL2N:0x00000000FE435860 is .data
# muhe @ muhe-NUC11PAHi5 in ~/Study/optee-fvp/linux on git:29aee39cf x [23:24:42] $ cat System.map | grep "primary_switched" ffff80000919032c t __primary_switched
for v in regex_constraints.variables() { if !variables.contains(v) { eprintln!("'{}' is not a valid query variable", v.red()); std::process::exit(1) } }
确定待解析源码文件(Verify that the --include and --exclude regexes are valid.) 主要是根据后缀来
随后就是通过管道来处理,分为:
文件读取 & AST解析 let (ast_tx, ast_rx) = mpsc::channel();
QueryTree 匹配 & 结果输出 let (results_tx, results_rx) = mpsc::channel();
1 2 3 4 5 6 7 8 9 10 11 12
// Spawn worker to iterate through files, parse potential matches and forward ASTs s.spawn(move |_| parse_files_worker(files, ast_tx, w, cpp));
// Run search queries on ASTs and apply CLI constraints // on the results. For single query executions, we can // directly print any remaining matches. For multi // query runs we forward them to our next worker function s.spawn(move |_| execute_queries_worker(ast_rx, results_tx, w, &args));
for i in0..query_results.len() { let (part1, part2) = query_results.split_at_mut(i + 1); let a = part1.last_mut().unwrap(); for b in part2 { filter(a, b); filter(b, a); } }
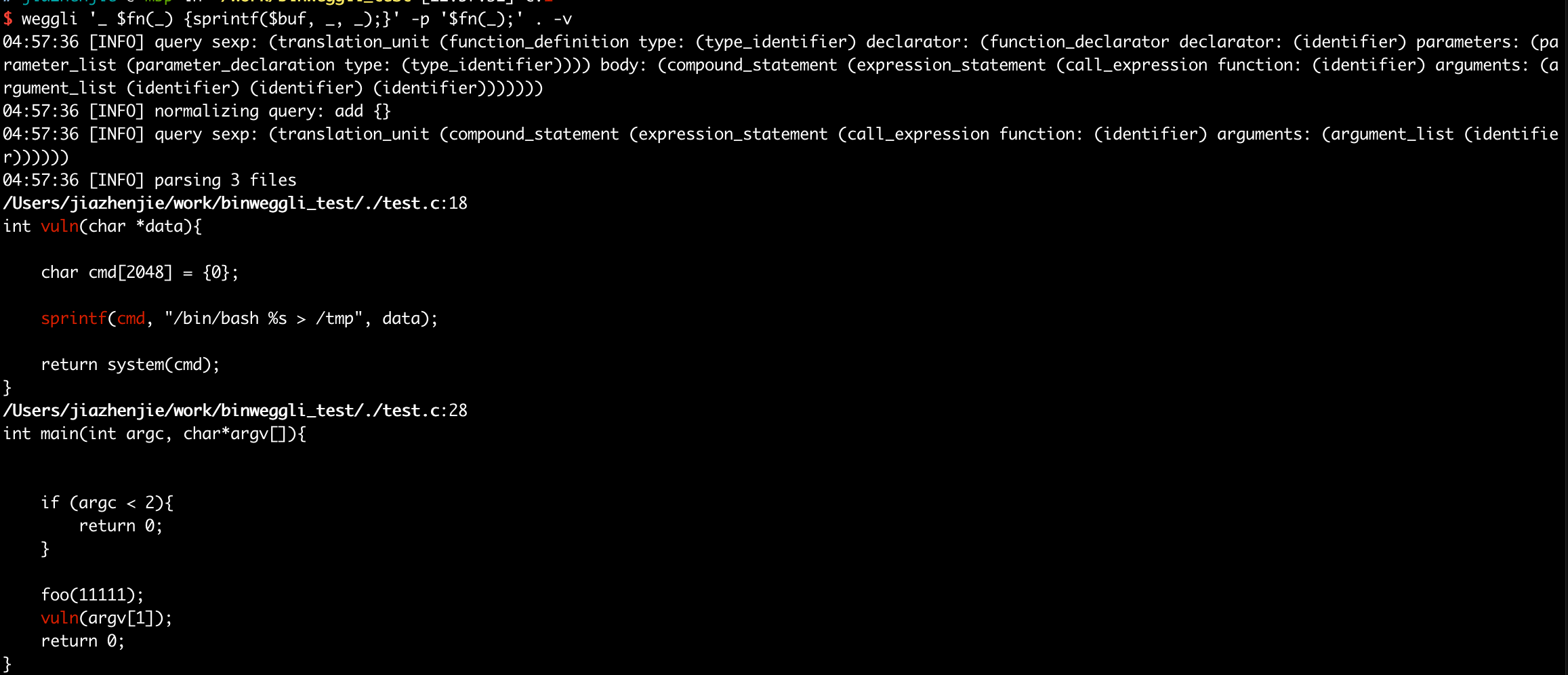
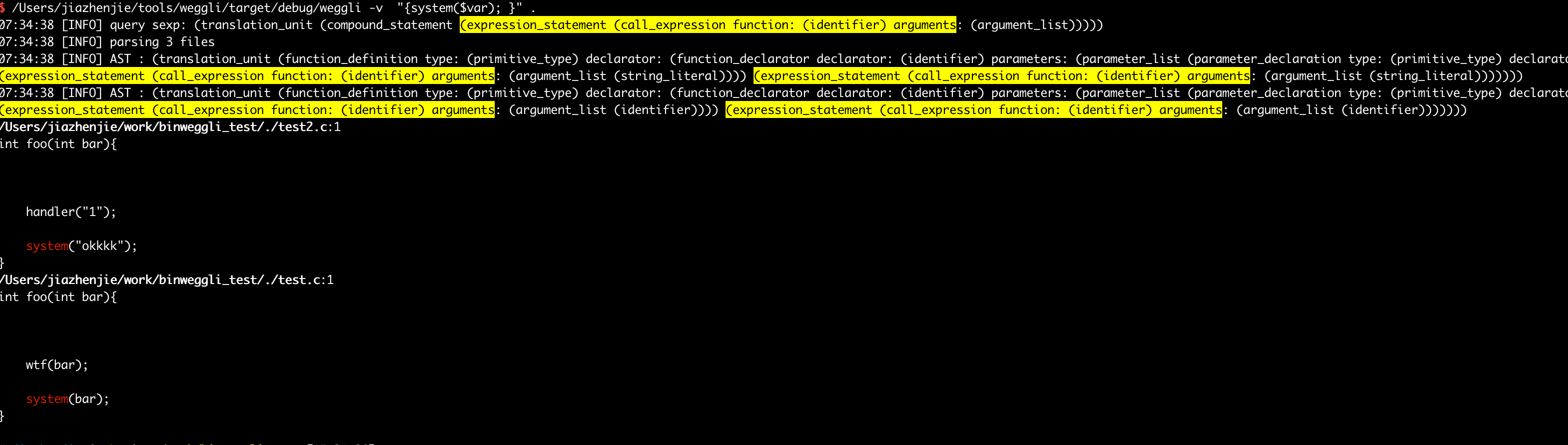
方便调试做的修改
1. 打印 query-tree 和 源码 AST方便定位问题
query-tree的话增加一个 -v 参数就行,会把query tree打印出来
少量代码测试这样是可以的,也可以使用log模块把信息打出来,不过数据太多了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
diff --git a/src/main.rs b/src/main.rs index a819c5c..caf9a51 100644 --- a/src/main.rs +++ b/src/main.rs @@ -468,6 +468,8 @@ fn execute_queries_worker( .enumerate() .for_each(|(i, WorkItem { qt, identifiers: _ })| { // Run query + let tmp_tree = tree.root_node().to_sexp(); + info!("AST : {}", tmp_tree); let matches = qt.matches(tree.root_node(), &source); if matches.is_empty() {
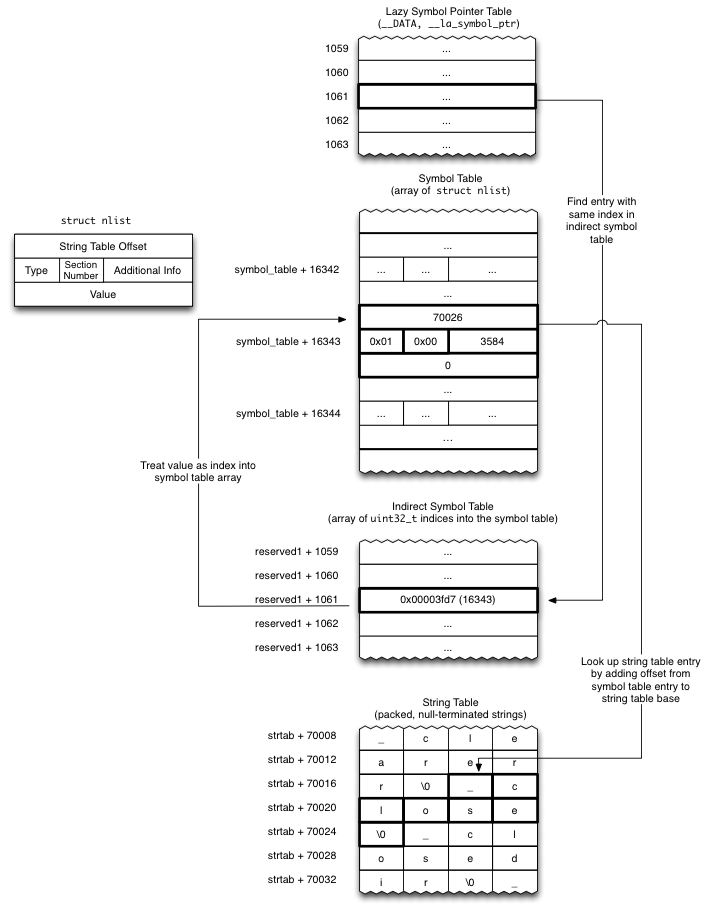
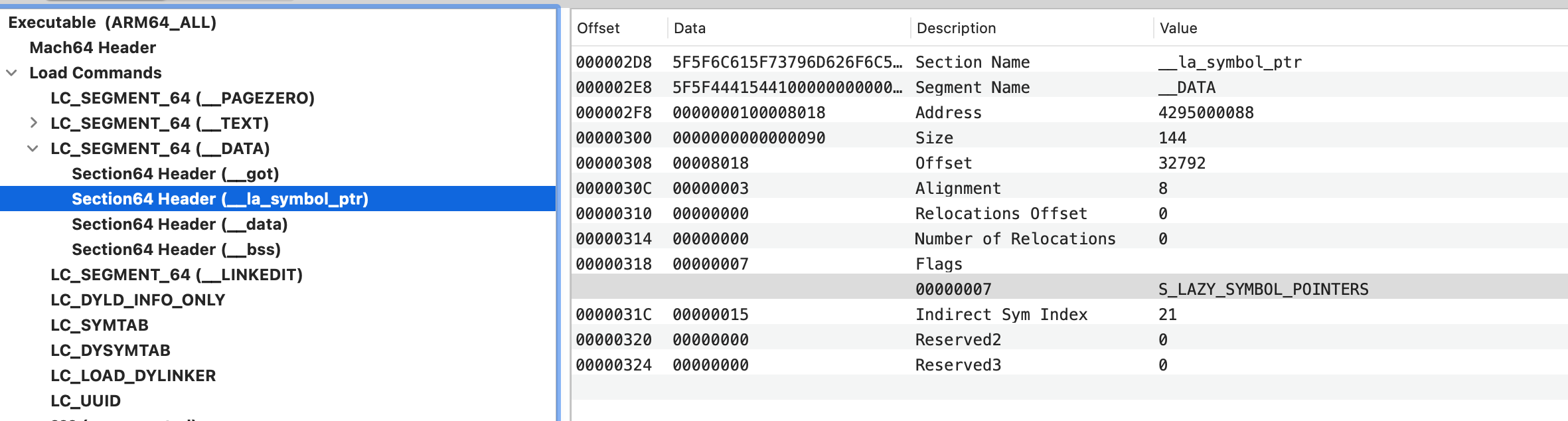
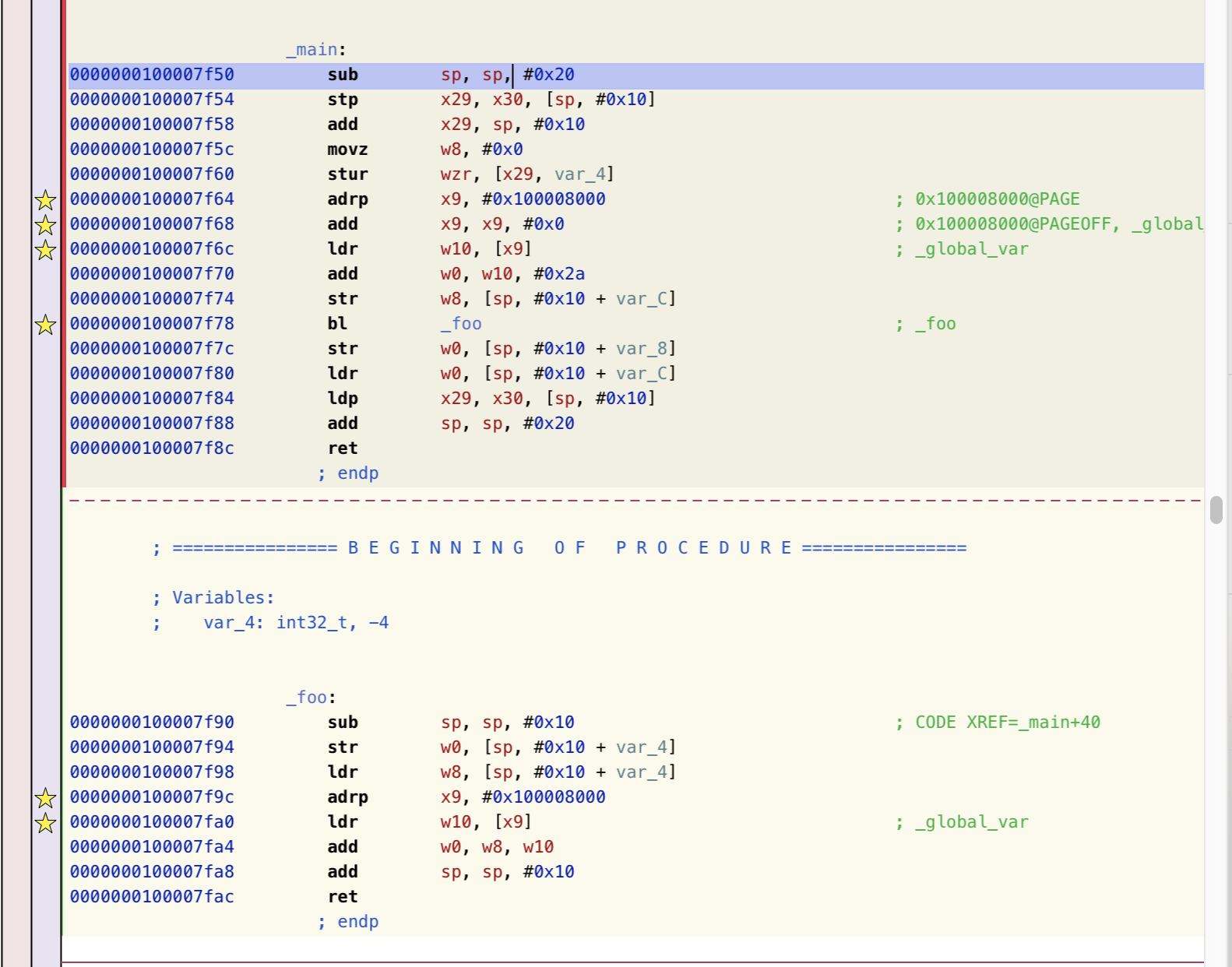
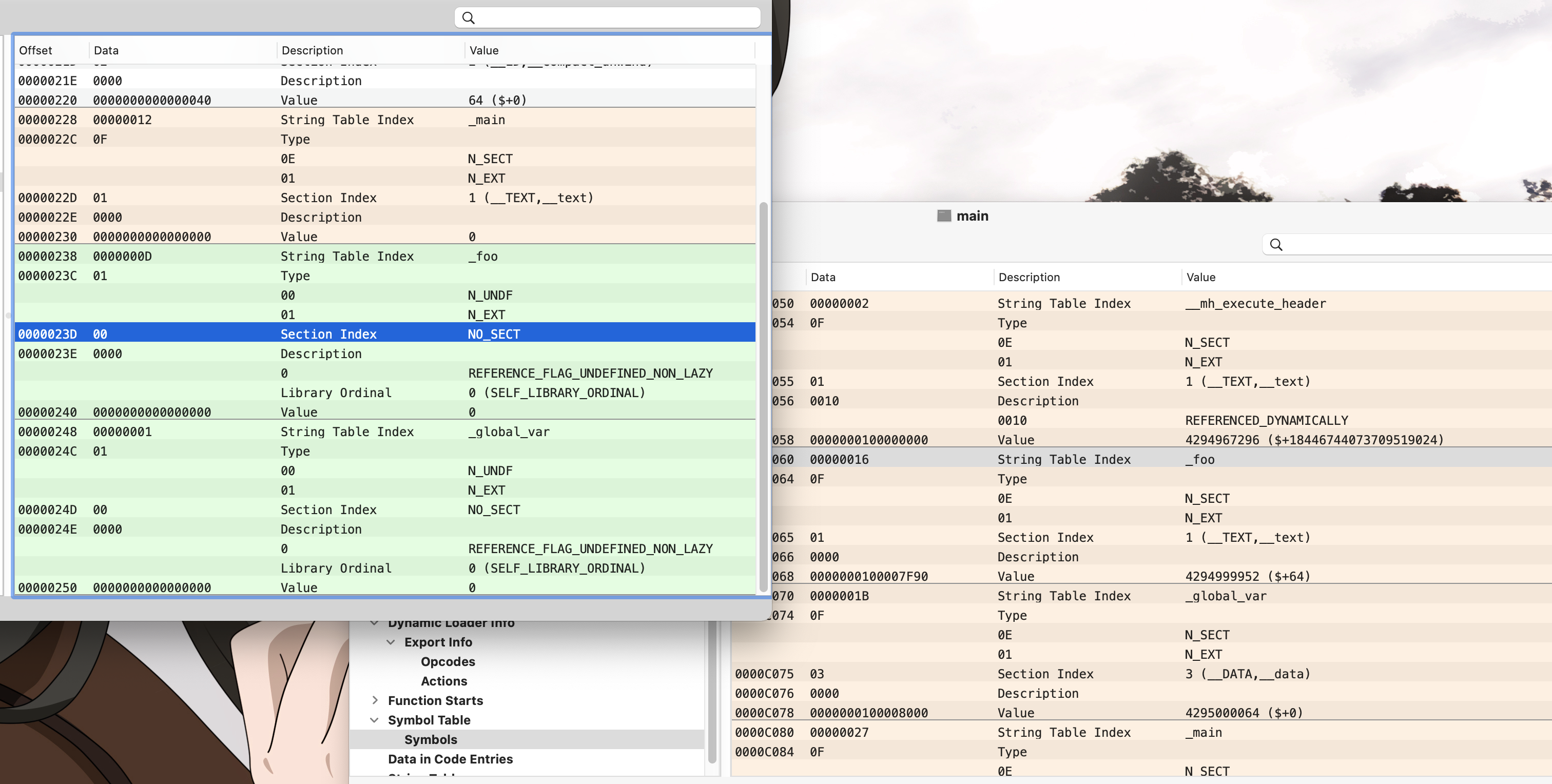
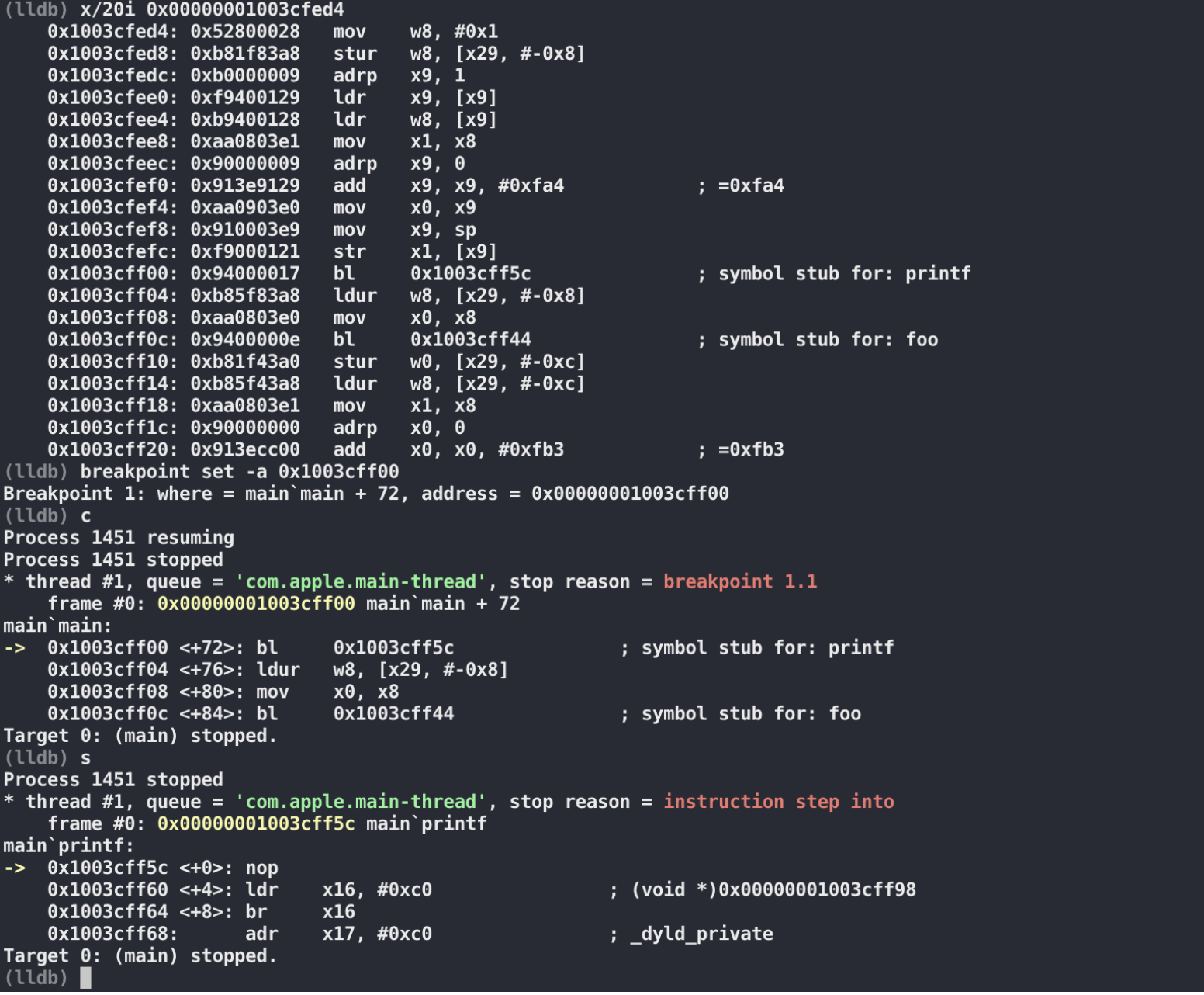
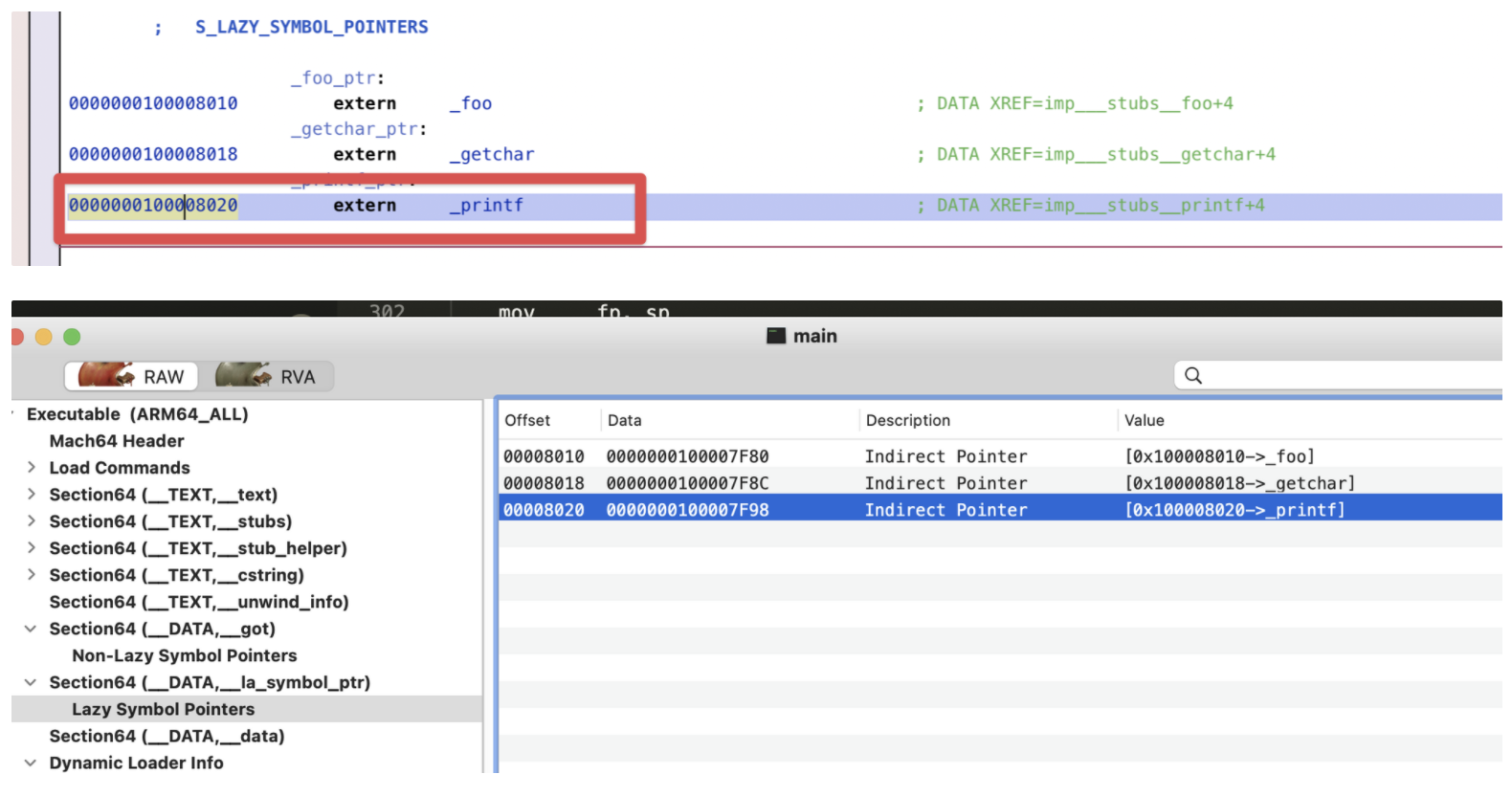
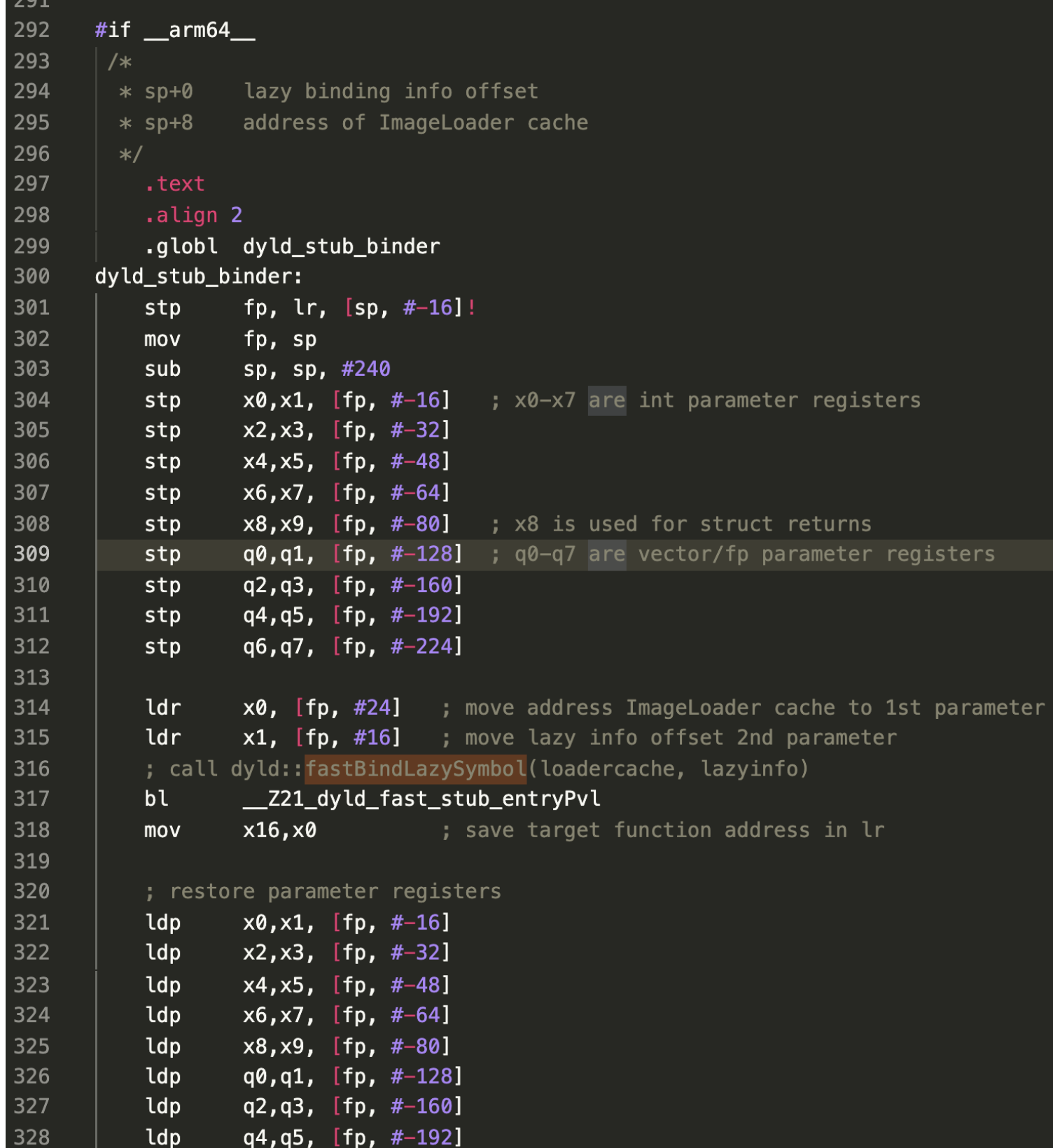
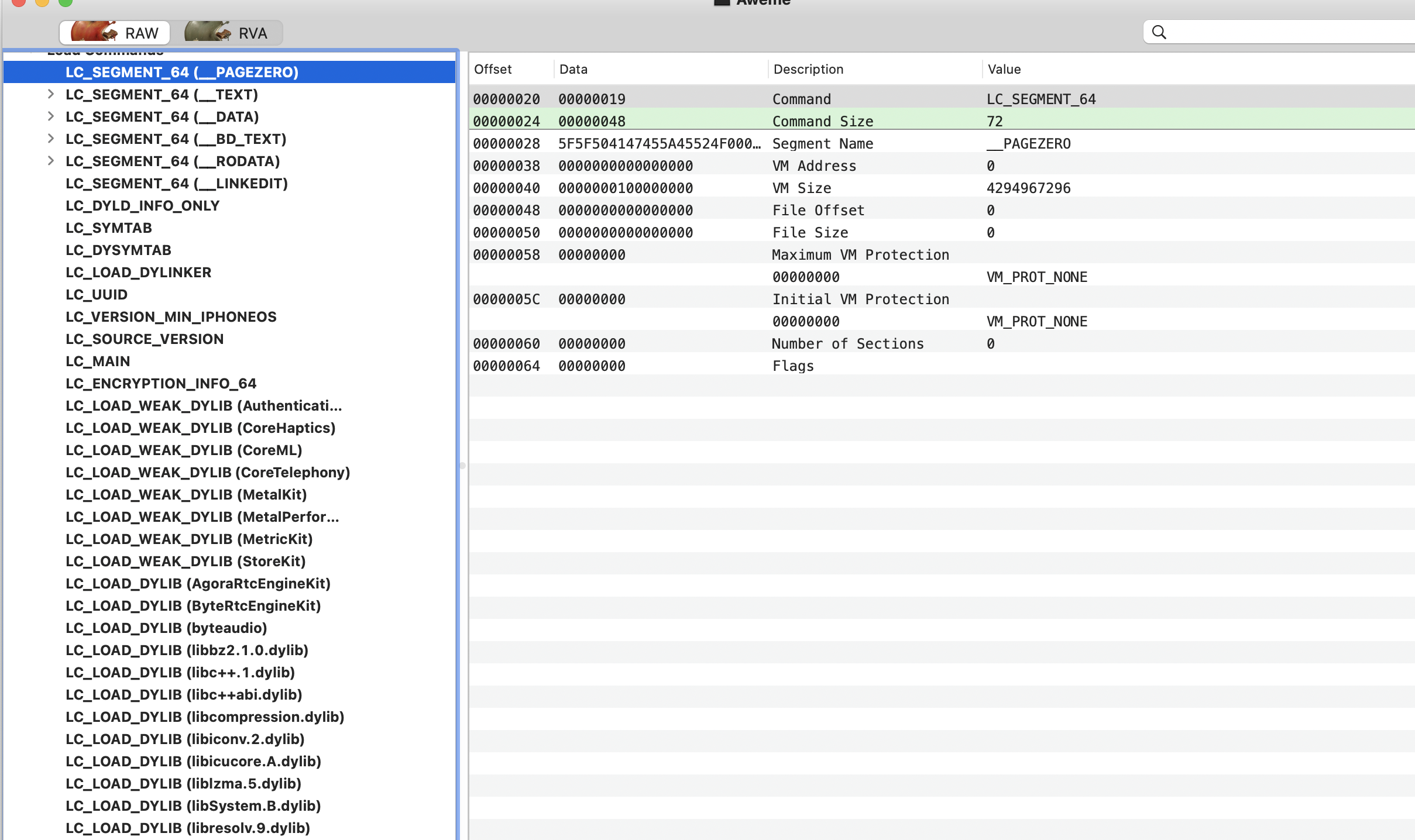
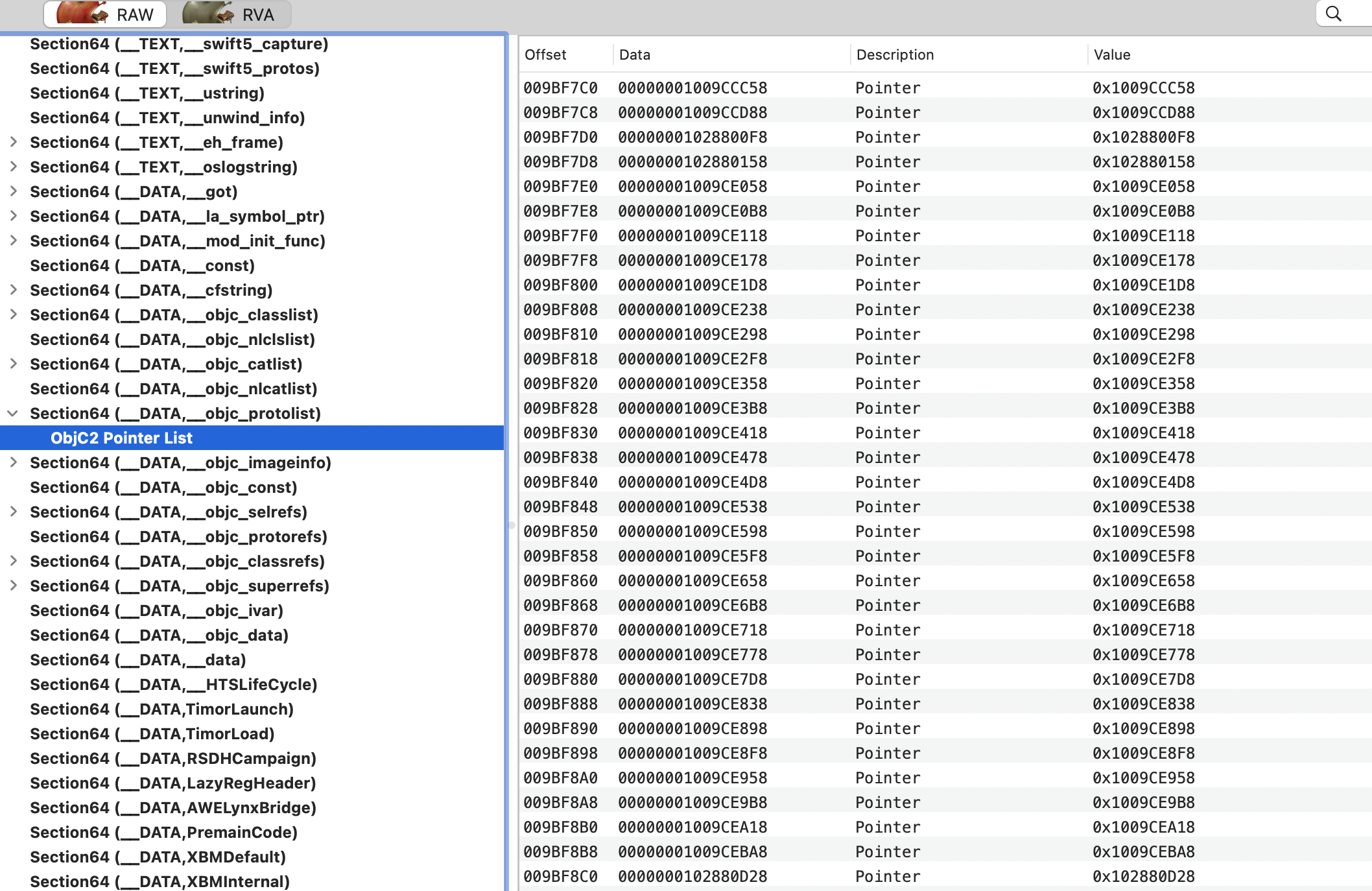
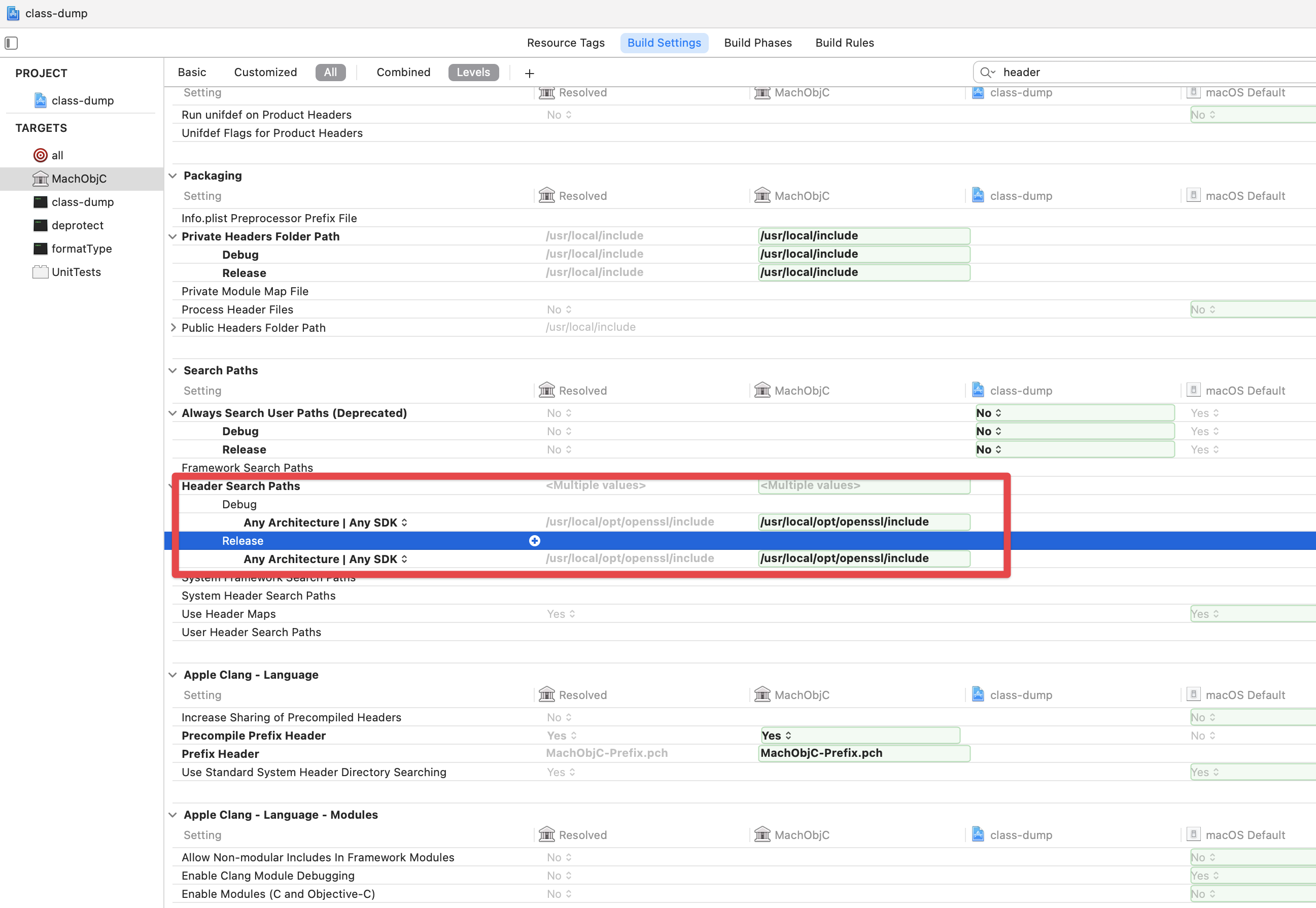
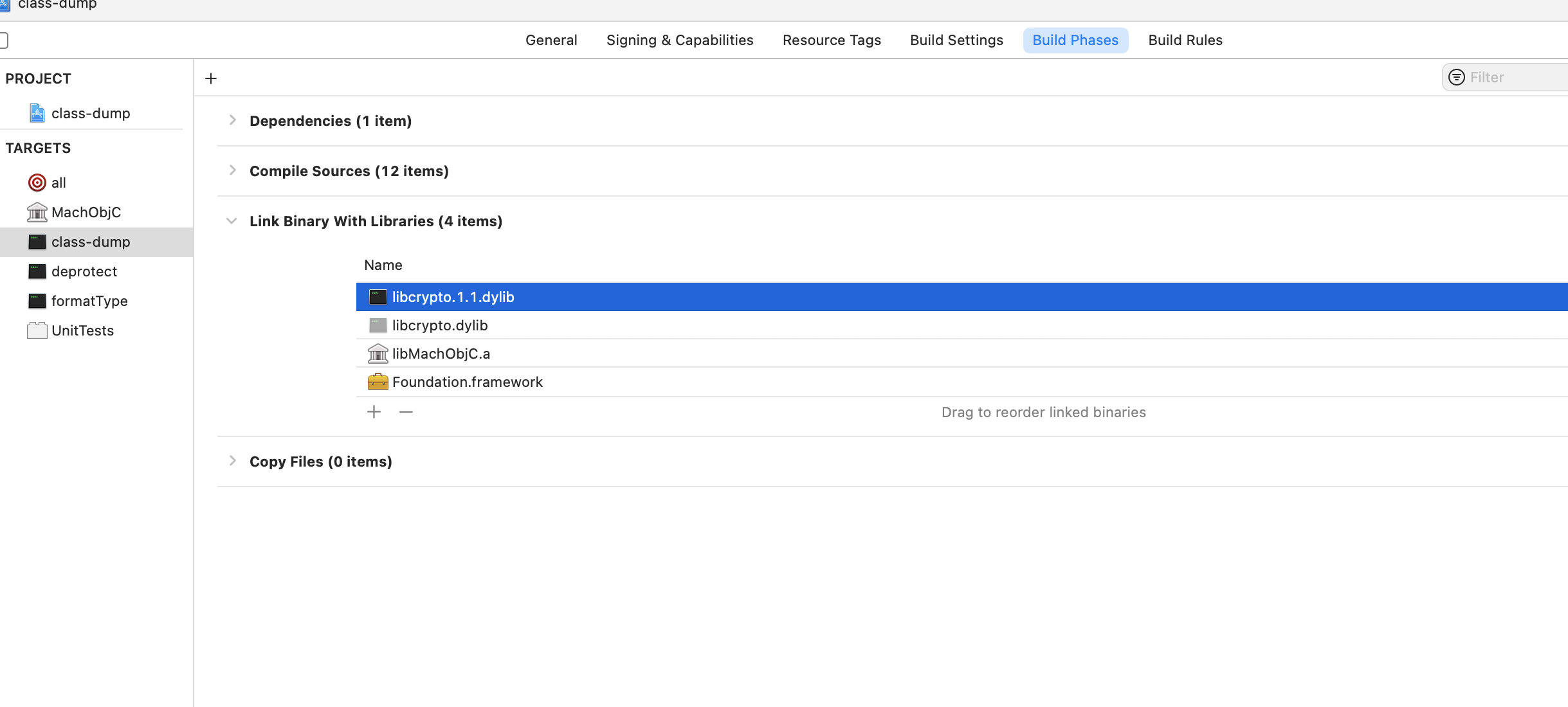
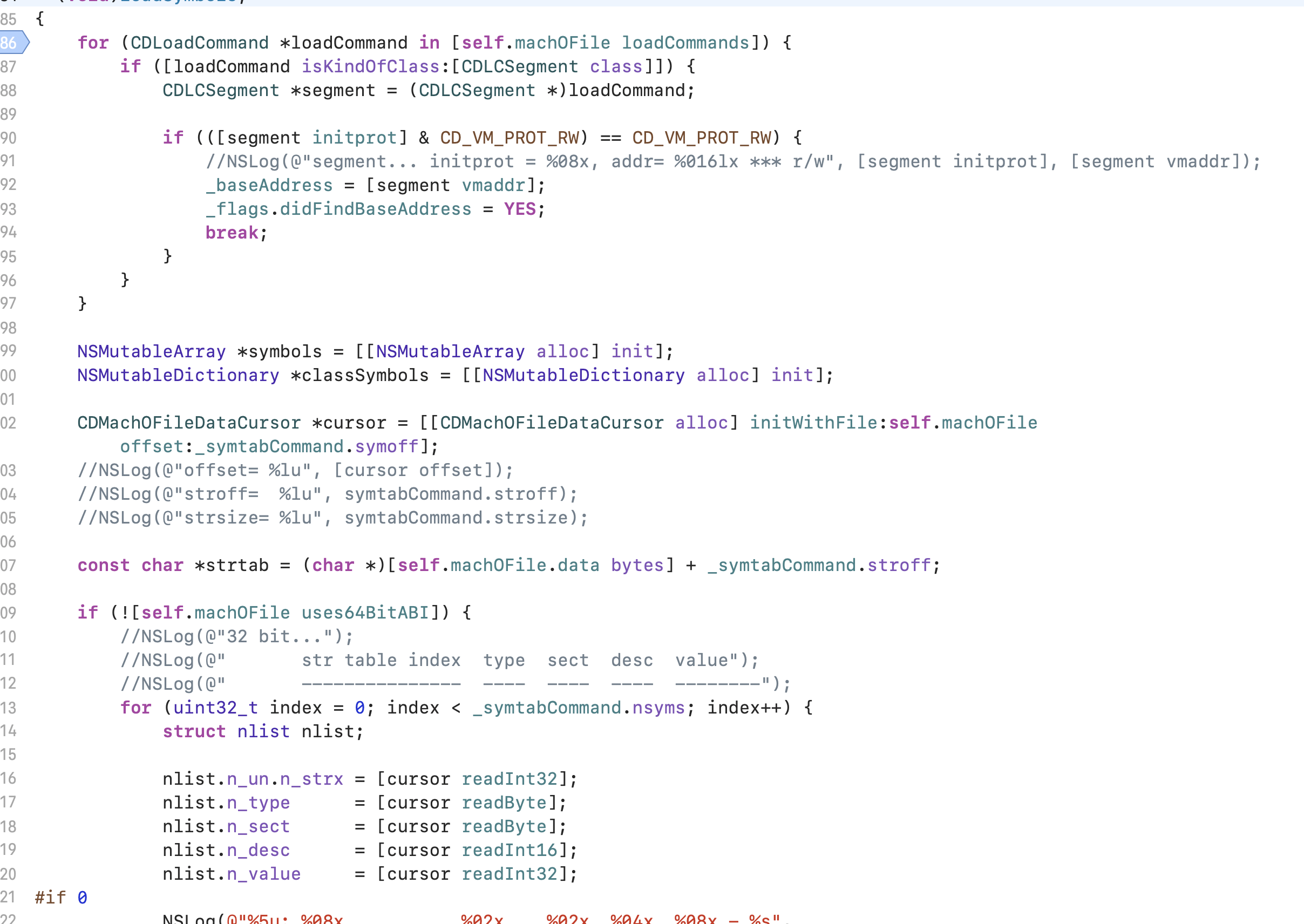
// Get indirect symbol table (array of uint32_t indices into symbol table) uint32_t *indirect_symtab = (uint32_t *)(linkedit_base + dysymtab_cmd->indirectsymoff);
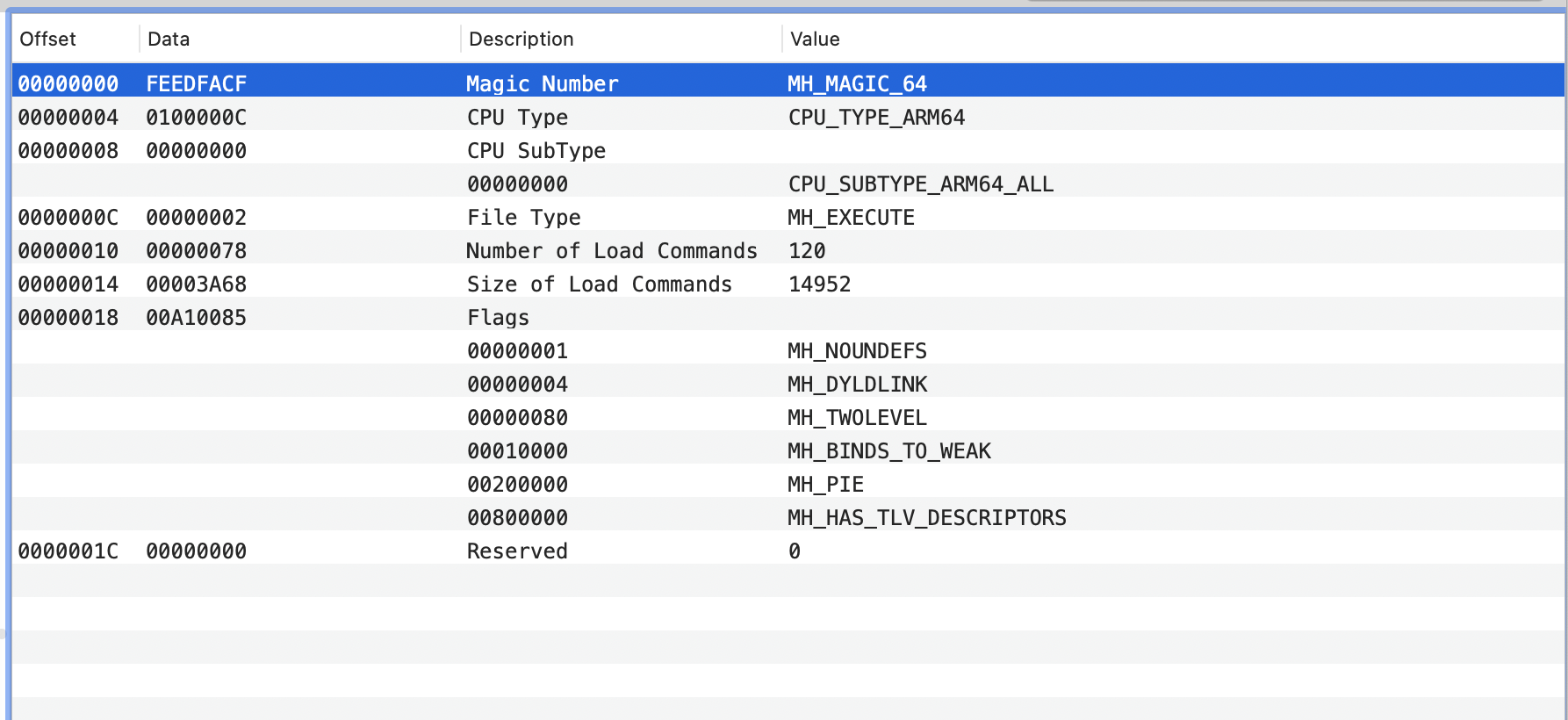
// Open our own binary and print out first 4 bytes (which is the same // for all Mach-O binaries on a given architecture) int fd = open(argv[0], O_RDONLY); uint32_t magic_number = 0; read(fd, &magic_number, 4); printf("Mach-O Magic Number: %x \\n", magic_number); close(fd);
struct relocation_info { int32_t r_address; /* offset in the section to what is being relocated */ uint32_t r_symbolnum:24, /* symbol index if r_extern == 1 or section ordinal if r_extern == 0 */ r_pcrel:1, /* was relocated pc relative already */ r_length:2, /* 0=byte, 1=word, 2=long, 3=quad */ r_extern:1, /* does not include value of sym referenced */ r_type:4; /* if not 0, machine specific relocation type */ };
struct nlist_64 { union { uint32_t n_strx; /* index into the string table */ } n_un; uint8_t n_type; /* type flag, see below */ uint8_t n_sect; /* section number or NO_SECT */ uint16_t n_desc; /* see <mach-o/stab.h> */ uint64_t n_value; /* value of this symbol (or stab offset) */ };
next = msghdr->msg_spot; for (len = 0; len < msgsz; len += msginfo.msgssz) { size_t tlen;
/* compare input (size_t) value against restrict (int) value */ if (msgsz > (size_t)msginfo.msgssz) { tlen = msginfo.msgssz; } else { tlen = msgsz; } if (next <= -1) { panic("next too low #3"); } if (next >= msginfo.msgseg) { panic("next out of range #3"); } SYSV_MSG_SUBSYS_UNLOCK(); eval = copyout(&msgpool[next * msginfo.msgssz], user_msgp, tlen); SYSV_MSG_SUBSYS_LOCK(); if (eval != 0) { #ifdef MSG_DEBUG_OK printf("error (%d) copying out message segment\\n", eval); #endif msg_freehdr(msghdr); wakeup((caddr_t)msqptr); goto msgrcvout; } user_msgp = user_msgp + tlen; /* ptr math */ next = msgmaps[next].next; }
Patch
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
for (len = 0; len < msgsz; len += msginfo.msgssz) { size_t tlen;
/* * copy the full segment, or less if we're at the end * of the message */ tlen = MIN(msgsz - len, (size_t)msginfo.msgssz); if (next <= -1) { panic("next too low #3"); } if (next >= msginfo.msgseg) { panic("next out of range #3"); } SYSV_MSG_SUBSYS_UNLOCK(); eval = copyout(&msgpool[next * msginfo.msgssz], user_msgp, tlen);
class Config extends TaintTracking::Configuration { Config() { this = "taint size to copy size" }
override predicate isSource(DataFlow::Node source) { exists(LocalVariable lv, Function f | isSYSCall(f) and lv.getFunction() = f and ( not source.asExpr().(Literal).isConstant() ) and lv.getAnAccess() = source.asExpr() ) }
override predicate isSink(DataFlow::Node sink) { exists (FunctionCall fc | fc.getTarget().getName() = "copyout" and fc.getArgument(2) = sink.asExpr() ) } }
from Config cfg, DataFlow::PathNode source, DataFlow::PathNode sink where cfg.hasFlowPath(source, sink) selectsource, " to ", sink, " in ", source.getNode().getFunction().getName()